![[R] 상관분석](/images/posts/index-r.png)
[R] 상관분석
상관분석은 두 변수가 서로 관련이 있는지 검정하는 통계 분석 기법입니다.
#01. 상관 분석의 이해
1) 상관 분석의 정의
정의
- 두 변수 간의 관계의 정도를 알아보기 위한 분석방법이다.
- 두 변수의 상관관계를 알아보기 위해 상관계수(Correlation coefficient )를 한다.
데이터(변량)간에 서로 관계하는 정도의 정량화
- 단일 변량의 산포 정도를 알아볼 경우 분산을 확인한다.
- 2변량 간의 산포 정도를 알아볼 경우 공분산이나 상관계수(정형화된 공분산)을 확인한다.
2) 공분산
정의
- 2개의 확률변수의 상관정도를 나타내는 값이다.(1개의 변수의 이산정도를 나타내는 분산과는 별개임)
- 만약 2개의 변수중 하나의 값이 상승하는 경향을 보일 때, 다른 값도 상승하는 경향의 상관관계에 있다면, 공분산의 값은 양수가 될 것이다.
- 반대로 2개의 변수중 하나의 값이 상승하는 경향을 보일 때, 다른 값이 하강하는 경향을 보인다면 공분산의 값은 음수가 된다.
numpy.cov()함수를 사용하면 x의 분산, y의 분산과 함께 x와 y의 공분산을 계산
공분산의 해석
부호
- 공분산이 +인 경우: 두 변수가 같은 방향으로 변화(하나가 증가하면 다른 하나도 증가)
- 공분산이 -인 경우: 두 변수가 반대 방향으로 변화(하나가 증가하면 다른 하나는 감소)
크기
공분산 = 0이면 두 변수가 독립, 즉, 한 변수의 변화로 다른 변수의 변화를 예측하지 못함- 공분산의 크기가 클 수록 두 변수는 함께 많이 변화
- 단위에 따라 공분산의 크기가 달라지므로 절대적 크기로 판단이 어려움
- 공분산을
-1 ~ 1범위로 표준화 시킨 것이 상관계수 - 주의: 공분산은 선형적인 관계를 측정하기 때문에 두 변수가 비선형적으로 함께 변하는 경우는 잘 측정하지 못함
3) 상관 계수 (Correlation Coefficient)
상관분석을 통해 도출한 값으로 두 변수가 얼마나 관련되어 있는지, 관련성의 정도를 파악할 수 있다.
- 상관계수는 0~1 사이의 값을 갖는다.
- 1에 가까울 수록 관련성이 크다는 의미.
- 양수면 정비례, 음수면 반비례 관계임을 의미.
| 상관 계수 범위 | 해석 |
|---|---|
| 0.7 < r ≤ 1 | 강한 양 (+)의 상관이 있다 |
| 0.3 < r ≤ 0.7 | 약한 양 (+)의 상관이 있다 |
| 0 < r ≤ 0.3 | 거의 상관이 없다 |
| r = 0 | 상관관계 (선형,직선)가 존재하지 않는다 |
| -0.3 ≤ r < 0 | 거의 상관이 없다 |
| -0.7 ≤ r < -0.3 | 약한 음 (-)의 상관이 있다 |
| -1 ≤ r < -0.7 | 강한 음 (-)의 상관이 있다 |
| 구분 | 피어슨 | 스피어만 |
|---|---|---|
| 개념 | 등간척도 이상으로 측정된 두 변수들의 상관 관계 측정 방식 | 서열척도인 두 변수들의 상관관계 측정 방식 |
| 특징 | 연속형 변수, 정규성 가정 대부분 많이 사용 |
순서형 변수, 비모수적 방법 순위를 기준으로 상관관계 측정 |
| 상관계수 | 피어슨 r (적률상관계수 ) | 순위상관계수 (p, 로우 ) |
3) 상관분석의 가설 검정
상관계수 $r$이 0이면 입력변수 $x$와 출력변수 $y$사이에는 아무런 관계가 없다 .
t 검정통계량을 통해 얻은 p-value 값이 0.05 이하인 경우, 대립가설을 채택하게 되어 우리가 데이터를 통해 구한 상관계수를 활용할 수 있게 된다 .
#02. 상관분석 R 구현 과정
1) 상관 분석을 위한 R 코드
분산
x <- c(1, 2, 3, 4, 5)
var(x, na.rm=TRUE)
💻 출력결과
2.5
공분산
x <- c(8, 3, 6, 6, 9, 4, 3, 9, 3, 4)
y <- c(6, 2, 4, 6, 10, 5, 1, 8, 4, 5)
cov(x, y)
💻 출력결과
5.61111111111111
상관계수
method 파라미터에 pearson, kendall, spearman중 선택적으로 지정 가능
x <- c(8, 3, 6, 6, 9, 4, 3, 9, 3, 4)
y <- c(6, 2, 4, 6, 10, 5, 1, 8, 4, 5)
cor(x, y, method="pearson")
💻 출력결과
0.862517279213578
상관분석
method 파라미터에 pearson, kendall, spearman중 선택적으로 지정 가능
x <- c(8, 3, 6, 6, 9, 4, 3, 9, 3, 4)
y <- c(6, 2, 4, 6, 10, 5, 1, 8, 4, 5)
cor.test(x, y, method="pearson")
💻 출력결과
Pearson's product-moment correlation
data: x and y
t = 4.821, df = 8, p-value = 0.00132
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.5096792 0.9670007
sample estimates:
cor
0.8625173
2) 샘플 데이터 준비
mcarts 데이터는 ggplot2에 내장된 샘플 데이터로 자동차 32종의 11개 속성에 대한 정보를 담고 있는 데이터이다.
패키지 가져오기
REPO_URL <- "https://cran.seoul.go.kr"
if (!require(ggplot2)) install.packages("ggplot2", repos=REPO_URL)
library(ggplot2)
샘플 데이터 준비
mtcars
💻 출력결과

3) 상관분석 수행
mpg(연비)와 cyl(실린더 수)의 공분산
결과값이 음수가 나오므로 연비와 실린더 수 간에는 반비례 관계가 있다고 해석.
cov(mtcars$mpg, mtcars$cyl)
💻 출력결과
-9.17237903225806
mpg(연비)와 cyl(실린더 수)의 상관계수
상관계수가 음수이므로 반비례.
0.7 ~ -1 사이 이므로 강하게 연관 있음.
cor(mtcars$mpg, mtcars$cyl)
💻 출력결과
-0.852161959426613
mpg(연비)와 cyl(실린더 수)의 상관분석
상관 분석은 R에 내장된 cor.test() 함수를 이용하여 수행할 수 있다.
상관계수(cor)가 -0.852162이므로 연비와 실린더 수는 반비례 관계이고, 1에 가까우므로 서로 연관성이 높다고 볼 수 있다.
또한 p-value가 6.113e-10로 유의수준 0.05보다 작게 나타나므로 mpg와 cyl이 상관관계가 있다고 볼 수 있다.
cor.test(mtcars$mpg, mtcars$cyl)
💻 출력결과
Pearson's product-moment correlation
data: mtcars$mpg and mtcars$cyl
t = -8.9197, df = 30, p-value = 6.113e-10
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.9257694 -0.7163171
sample estimates:
cor
-0.852162
cyl(실린더 수)와 wt(무게)의 상관분석
상관계수(cor)가 0.7824958이므로 실린더가 많을 수록 더 무거운 경향이 있다는 것을 알 수 있다.
cor.test(mtcars$cyl, mtcars$wt)
💻 출력결과
Pearson's product-moment correlation
data: mtcars$cyl and mtcars$wt
t = 6.8833, df = 30, p-value = 1.218e-07
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.5965795 0.8887052
sample estimates:
cor
0.7824958
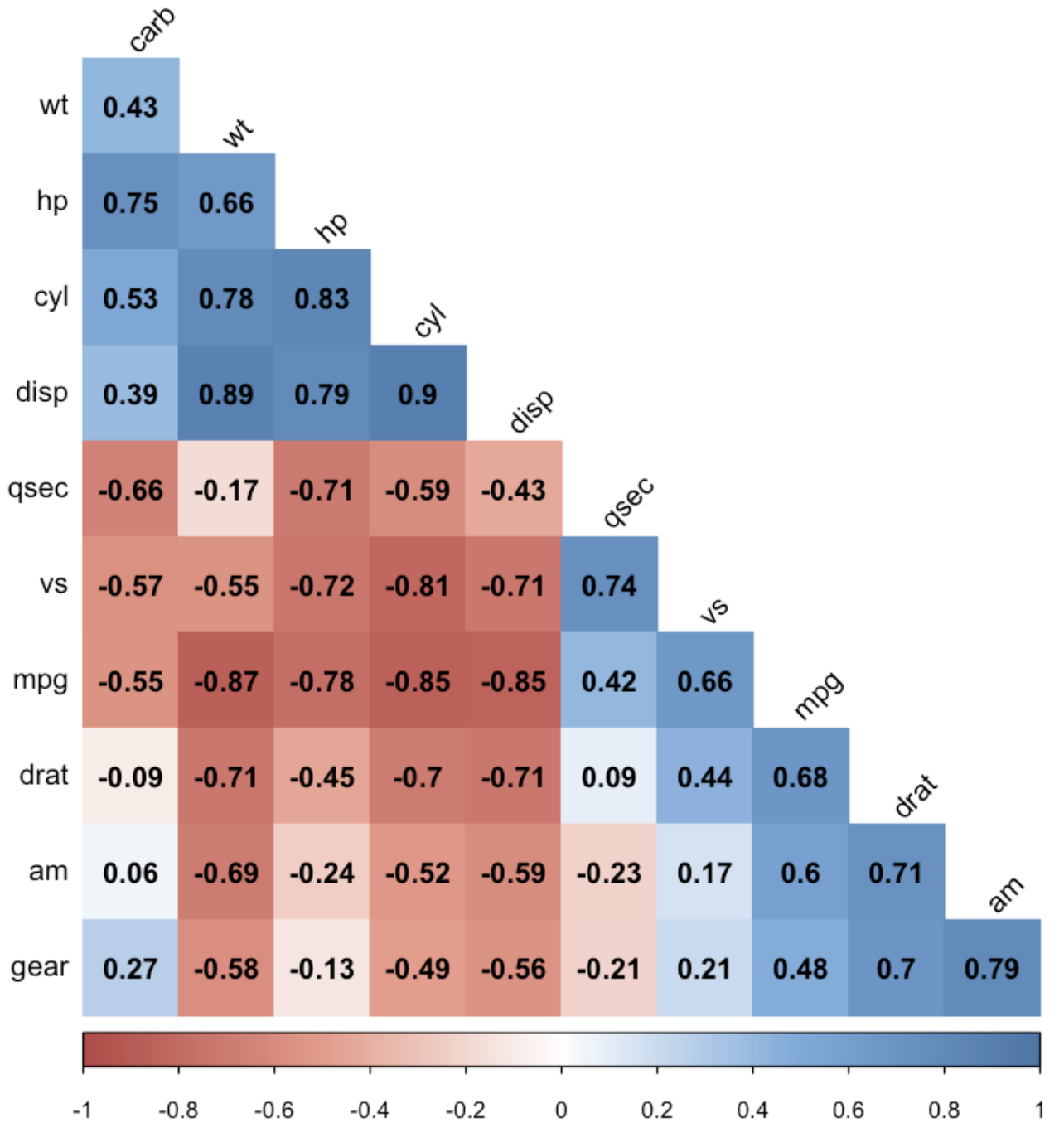
#03. 상관분석 시각화 하기
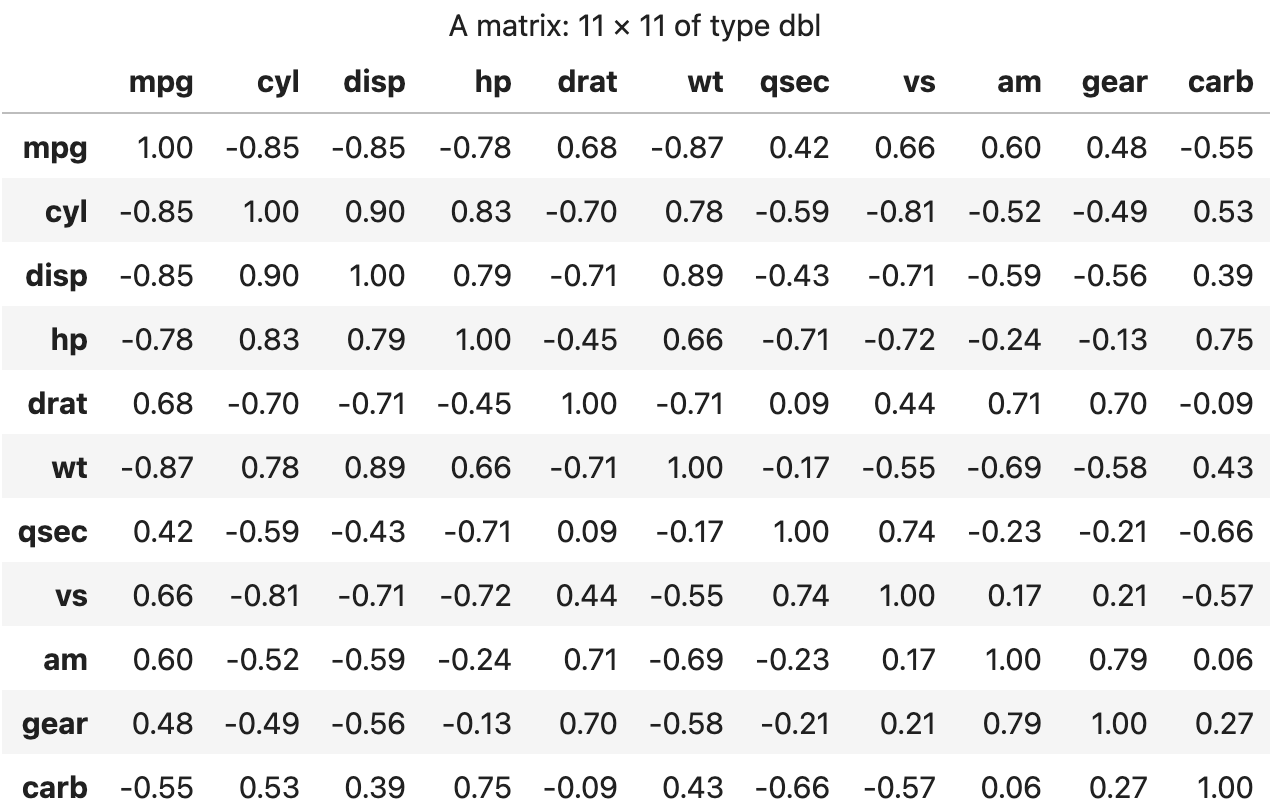
1) 상관 행렬
여러 변수의 관련성을 한 번에 알아보고기 위해 모든 변수의 상관 관계를 나타낸 행렬로서 각 변수가 서로 교차하는 지점이 두 변수간의 상관계수이다.
상관행렬을 보면 어떤 변수끼리 관련이 크고 적은지 파악할 수 있다.
car_cor <- cor(mtcars)
round(car_cor, 2) # 소수점 셋째 자리에서 반올림해서 출력
💻 출력결과
2) 상관행렬 히트맵
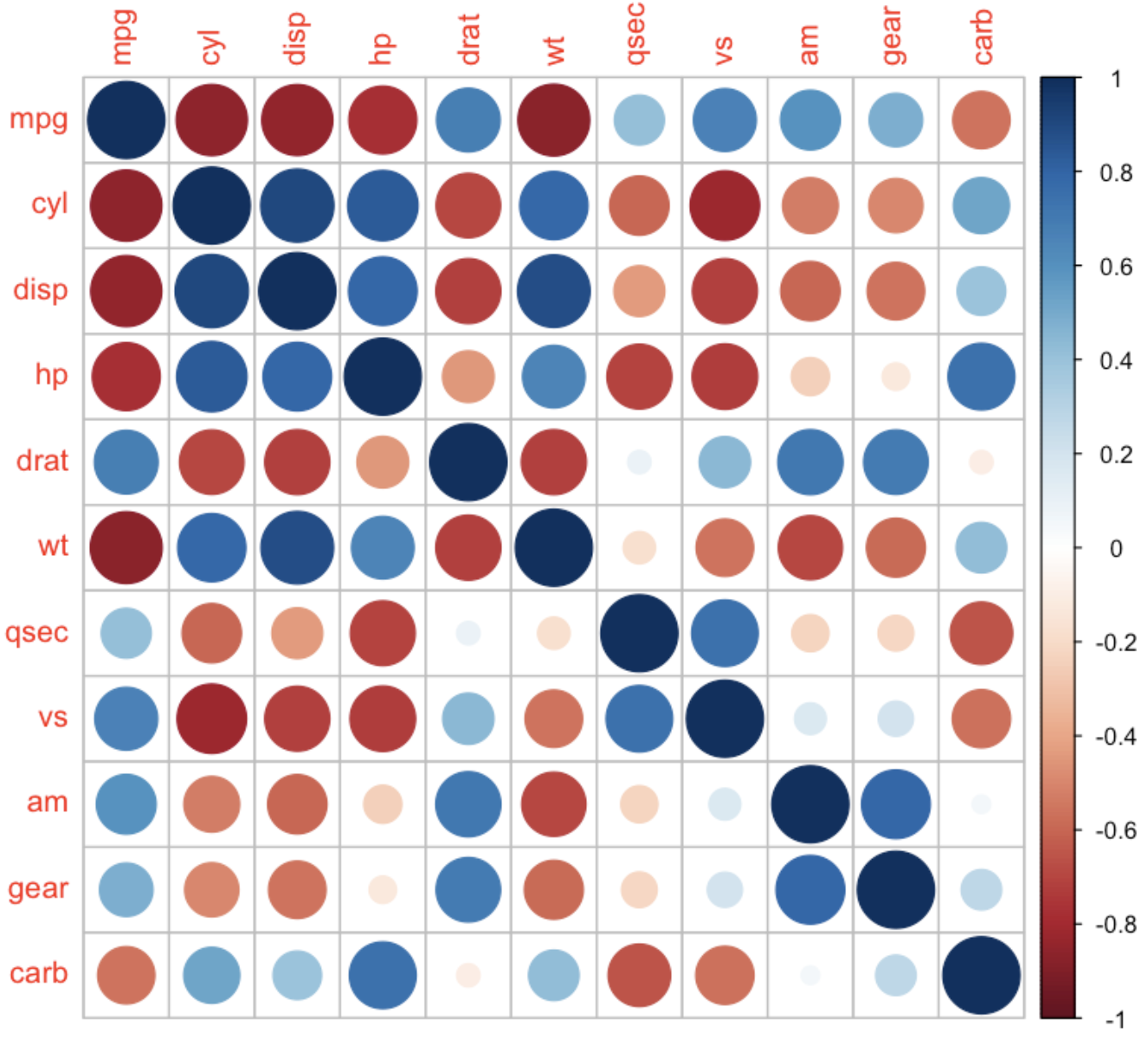
상관행렬을 그래프로 표시한 형태를 상관행렬 히트맵.
corrplot 패키지를 이용해 상관행렬에서 상관계수 값의 크기를 색상으로 표현한 그래프로 구성할 수 있다.
기본 사용 방법
패키지 가져오기
REPO_URL <- "https://cran.seoul.go.kr"
if (!require(corrplot)) install.packages("corrplot", repos=REPO_URL)
library(corrplot)
상관행렬 히트맵 기본 구현
corrplot(car_cor)
💻 출력결과
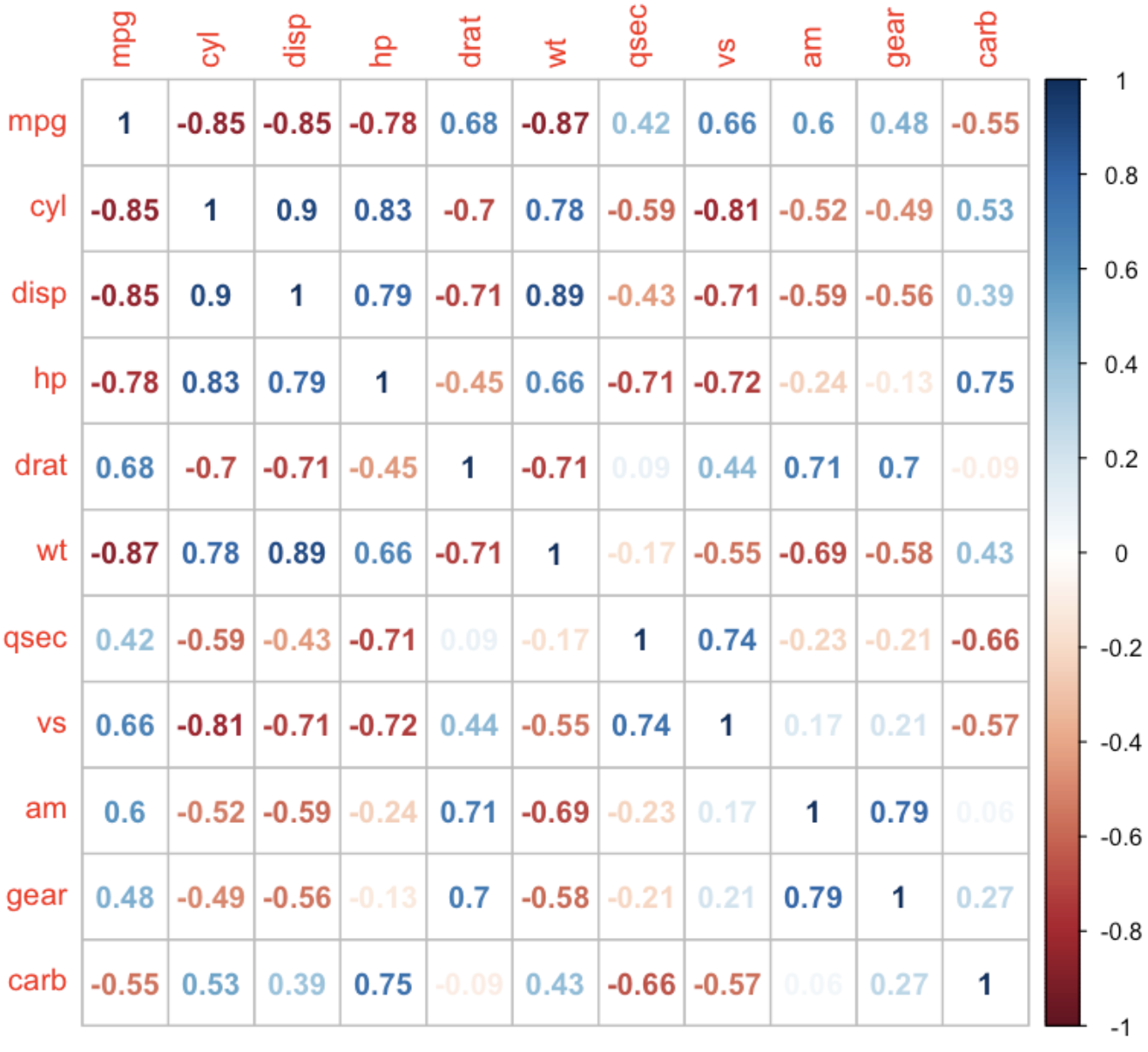
원 대신 상관계수를 출력하기
corrplot(car_cor, method = "number")
💻 출력결과
옵션 지정하기
# 사용할 색상 목록 생성
col <- colorRampPalette(c("#BB4444", "#EE9988", "#FFFFFF", "#77AADD", "#4477AA"))
# 상세 옵션을 지정한 히트맵 생성
corrplot(car_cor, # 상관행렬
method = "color", # 색깔로 표현
col = col(200), # 색상 200개 선정
type = "lower", # 왼쪽 아래 행렬만 표시
order = "hclust", # 유사한 상관계수끼리 군집화
addCoef.col = "black", # 상관계수 색깔
tl.col = "black", # 변수명 색깔
tl.srt = 45, # 변수명 45도 기울임
diag = FALSE) # 대각 행렬 제외
💻 출력결과
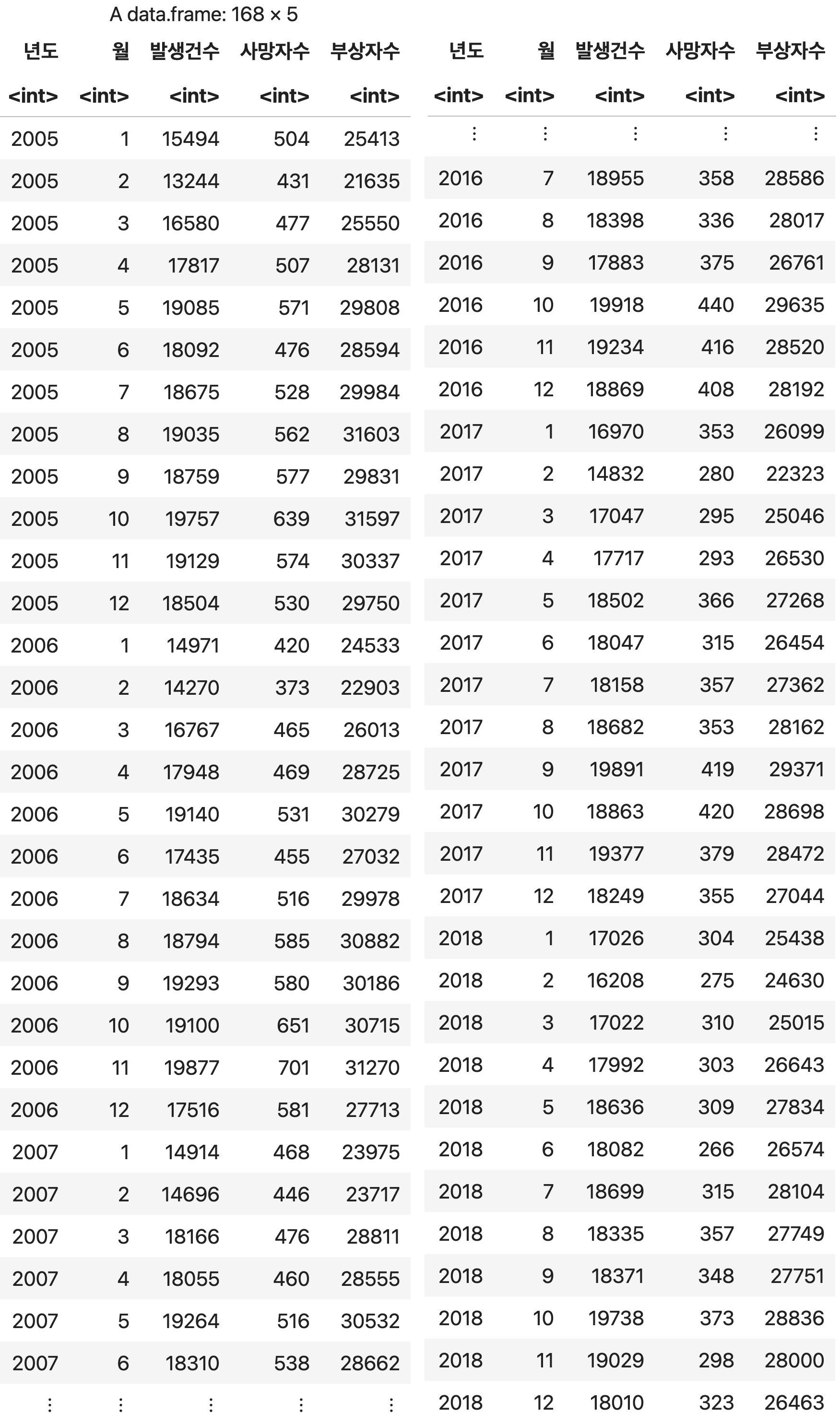
#04. 교통사고 발생건수와 부상자 수의 상관관계 분석
1) 샘플 데이터 가져오기
2005~2018년도 월별 교통사고 현황 데이터.
데이터 출처: 국가통계포털
교통사고 데이터 가져오기
교통사고 <- read.csv("http://itpaper.co.kr/demo/r/traffic.csv", stringsAsFactors=F, fileEncoding="euc-kr")
교통사고
💻 출력결과
2) 교통사고 발생건수와 부상자수에 대한 상관분석
상관계수(cor)가 0.9467014 이므로 교통사고 발생건수와 부상자 수는 아주 밀접한 관계가 있다.
교통사고 발생건수와 부상자수에 대한 상관 분석
cor.test(교통사고$발생건수, 교통사고$부상자수)
💻 출력결과
Pearson's product-moment correlation
data: 교통사고$발생건수 and 교통사고$부상자수
t = 37.867, df = 166, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.9283630 0.9604416
sample estimates:
cor
0.9467014
3) 교통사고 발생건수와 사망자수에 대한 상관분석
상관계수(cor)가 0.3506018 이므로 교통사고 발생건수와 사망자수는 큰 관계가 없다.
교통사고 발생건수와 사망자수에 대한 상관분석
cor.test(교통사고$발생건수, 교통사고$사망자수)
💻 출력결과
Pearson's product-moment correlation
data: 교통사고$발생건수 and 교통사고$사망자수
t = 4.8234, df = 166, p-value = 3.175e-06
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.2103588 0.4767059
sample estimates:
cor
0.3506018
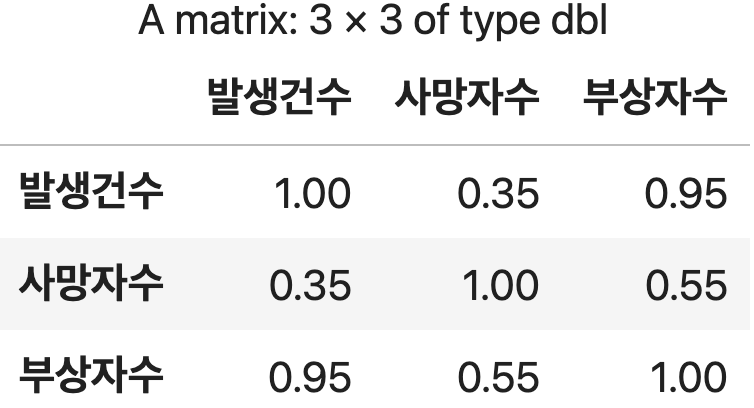
4) 상관 행렬 확인하기
패키지 가져오기
REPO_URL <- "https://cran.seoul.go.kr"
if (!require(dplyr))install.packages("dplyr", repos=REPO_URL)
library(dplyr)
상관행렬
dplyr 패키지의 select() 함수를 사용해서 교통사고` 데이터 중 필요한 변수만 추출하여 새로운 데이터프레임으로 재구성
df <- 교통사고 %>% select(c(발생건수,사망자수,부상자수))
교통사고_상관관계 <- cor( df )
round(교통사고_상관관계, 2)
💻 출력결과
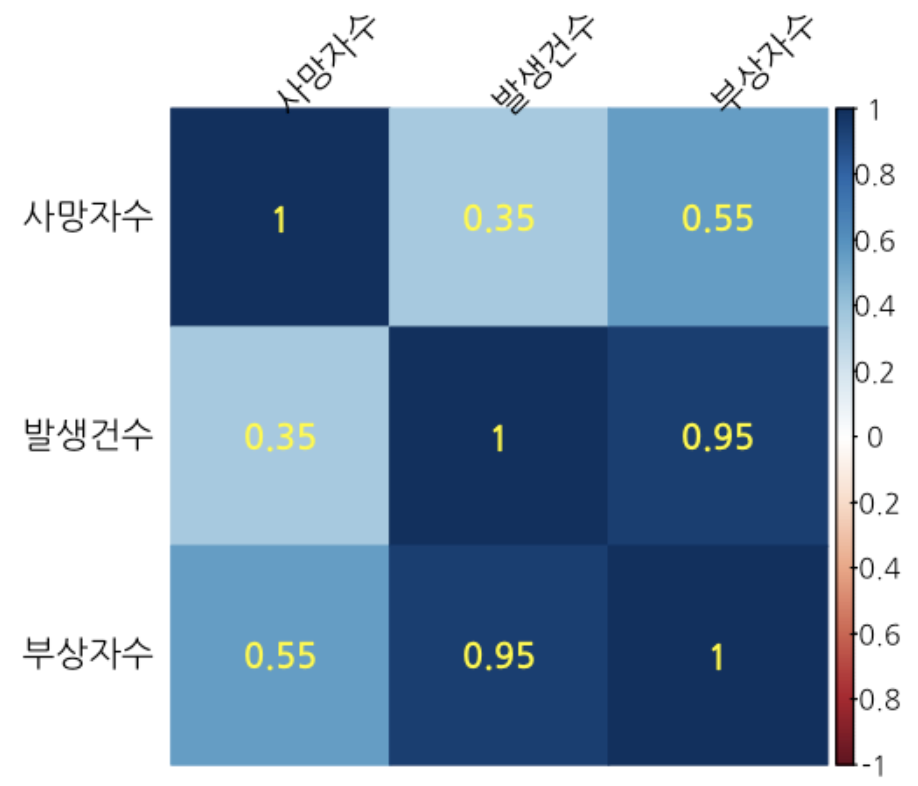
5) 히트맵을 통한 시각화
패키지 가져오기
REPO_URL <- "https://cran.seoul.go.kr"
if (!require(extrafont)) install.packages("extrafont", repos=REPO_URL)
library(extrafont)
기본 옵션 설정
# 그래프 가로, 세로크기, 불필요한 경고 메시지 끄기
options(repr.plot.width=5, repr.plot.height=5, warn=-1)
한글 글꼴 로드
# 폰트 로드하기
font_import(pattern = 'NanumGothic')
# mac의 경우 `device="win"` 생략
loadfonts(device="win")
히트맵 시각화 구현
# 색상 그룹 지정
col <- colorRampPalette(c("#BB4444", "#EE9988", "#FFFFFF", "#77AADD", "#4477AA"))
# 한글 글꼴 지정
par(family = "NanumGothic")
# 시각화
corrplot(교통사고_상관관계, # 상관행렬
method = "color", # 색깔로 표현
order = "hclust", # 유사한 상관계수끼리 군집화
addCoef.col = "yellow", # 상관계수 색깔
tl.col = "black", # 변수명 색깔
tl.srt = 45, # 변수명 45도 기울임
diag = FALSE) # 대각 행렬 제외
💻 출력결과
5) 교통사고 발생건수와 부상자수의 상관관계
ggplot2 패키지를 사용하여 산점도 그래프를 시각화 한다.
ggplot(data=데이터프레임, aes(x=독립변수, y=종속변수)) +
geom_point(size=숫자, colour='색상) +
... 각종 옵션을 처리하는 함수들을 `+` 로 연결 ...
패키지 준비하기
REPO_URL <- "https://cran.seoul.go.kr"
if (!require(ggplot2))install.packages("ggplot2", repos=REPO_URL)
library(ggplot2)
기본 옵션 설정
options(repr.plot.width=15, repr.plot.height=10, warn=-1)
교통사고 발생건수와 부상자수의 상관관계 산점도 그래프
ggplot(data=교통사고, aes(x=발생건수, y=부상자수)) +
geom_point(size=3, colour='blue') +
# 배경을 흰색으로 설정
theme_bw() +
# 그래프 타이틀 설정
ggtitle("교통사고 발생건수와 부상자 수의 상관관계") +
# x축 제목 설정 --> 표시안함을 위해 빈 문자열 설정
xlab("발생건수") +
# y축 제목 설정 --> 표시안함을 위해 빈 문자열 설정
ylab("부상자수") +
# 각 텍스트의 색상, 크기, 각도, 글꼴 설정
theme(plot.title=element_text(family="NanumGothic", color="#0066ff", size=25, face="bold"),
axis.title.x=element_text(family="NanumGothic", color="#999999", size=18, face="bold"),
axis.title.y=element_text(family="NanumGothic", color="#999999", size=18,face="bold", hjust=1),
axis.text.x=element_text(family="NanumGothic", color="#000000", size=16, angle=45),
axis.text.y=element_text(family="NanumGothic", color="#000000",size=16, angle=45))
💻 출력결과
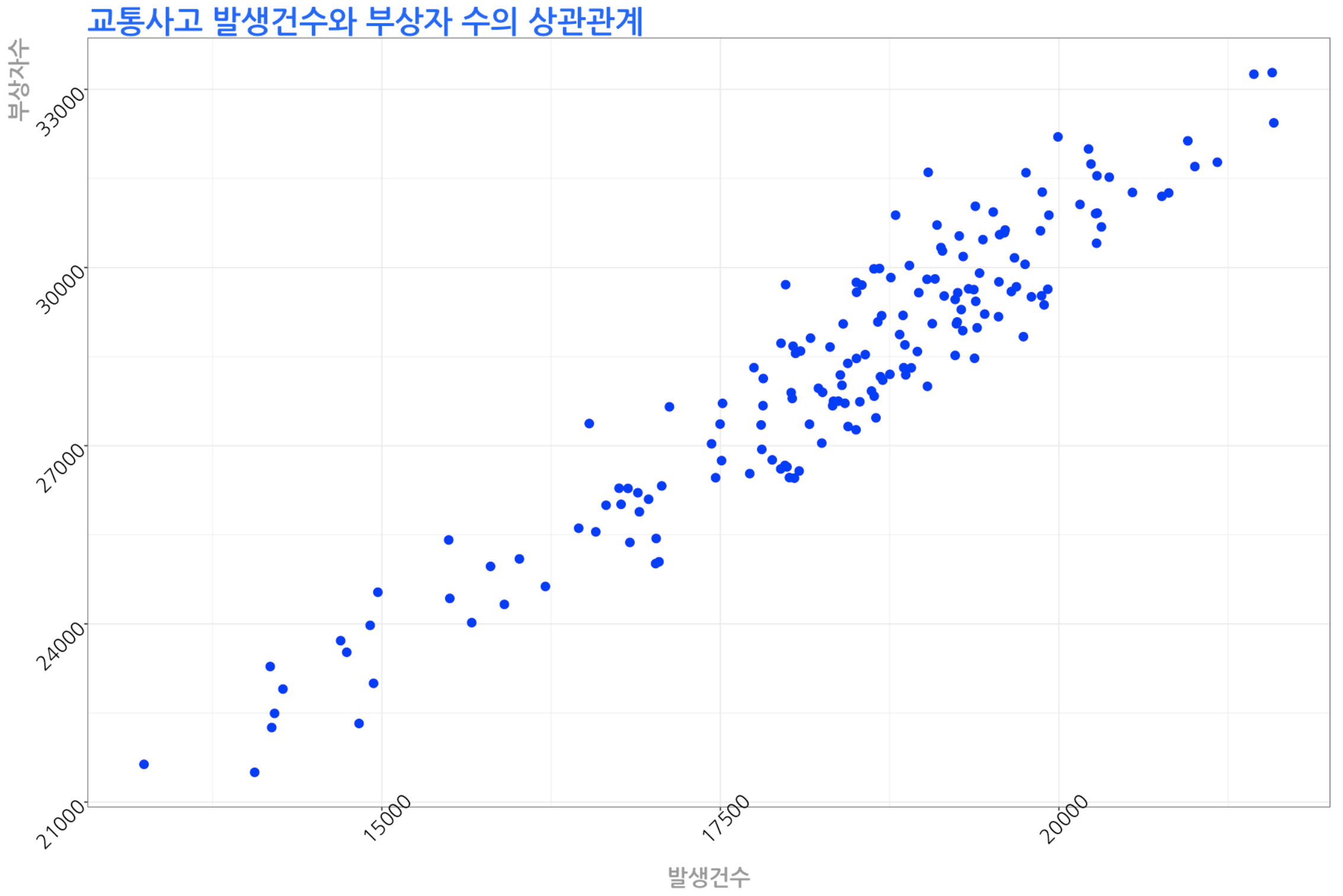
6) 교통사고 발생건수와 사망자수의 상관관계
앞에서 이미 필요한 패키지 로드, 기본 옵션등을 설정해 놓았으므로 그래프를 바로 구현한다.
교통사고 발생건수와 사망자수의 상관관계 산점도 그래프
ggplot(data=교통사고, aes(x=발생건수, y=사망자수)) +
geom_point(size=3, colour='#ff6600') +
# 배경을 흰색으로 설정
theme_bw() +
# 그래프 타이틀 설정
ggtitle("교통사고 발생건수와 사망자 수의 상관관계") +
# x축 제목 설정 --> 표시안함을 위해 빈 문자열 설정
xlab("발생건수") +
# y축 제목 설정 --> 표시안함을 위해 빈 문자열 설정
ylab("부상자수") +
# 각 텍스트의 색상, 크기, 각도, 글꼴 설정
theme(plot.title=element_text(family="NanumGothic", color="#ff0000", size=25, face="bold"),
axis.title.x=element_text(family="NanumGothic", color="#999999", size=18, face="bold"),
axis.title.y=element_text(family="NanumGothic", color="#999999", size=18,face="bold", hjust=1),
axis.text.x=element_text(family="NanumGothic", color="#000000", size=16, angle=45),
axis.text.y=element_text(family="NanumGothic", color="#000000", size=16, angle=45))
💻 출력결과
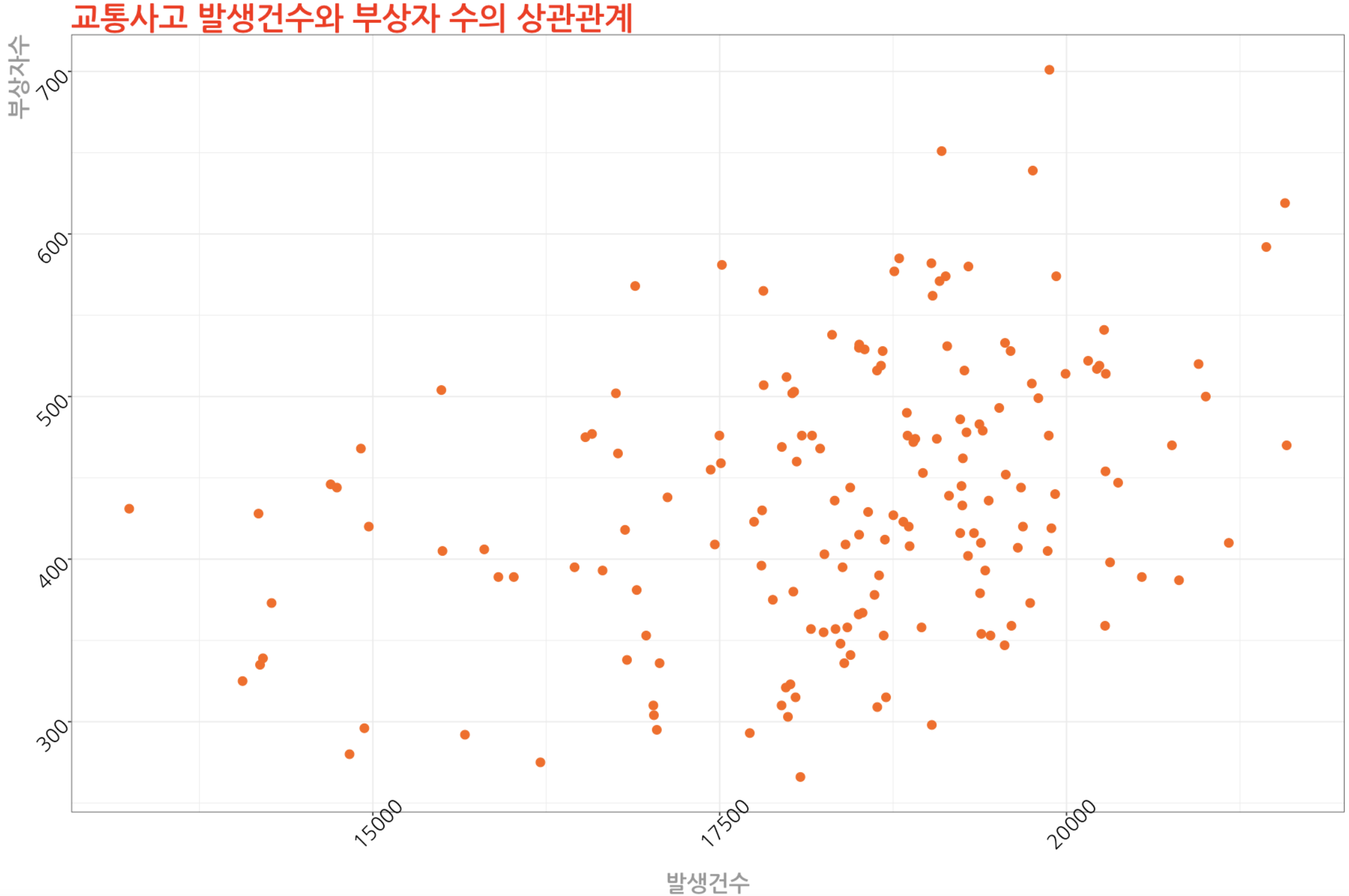
7) R에서 추세선 그리기
산점도 그래프를 그리는 코드의 geom_point() 함수 다음 라인 위치에 stat_smooth(method = 'lm', se=F, color='black') 를 옵션으로 추가한다.
method='lm'선형 회귀분석을 수행함. 생략시 국소 회귀분석으로 동작.se=F추세선 주변의 표준오차영역(회색음영)을 표시하지 않는다. (권장)color='색상값'추세선의 색상을 표시한다.- 교통사고 발생 건수와 부상자의 상관관계에 대한 추세선
ggplot(data=교통사고, aes(x=발생건수, y=부상자수)) +
geom_point(size=3, colour='blue') +
# 추세선 추가하기
stat_smooth(method = 'lm', se=F, color='#ff0000') +
# 배경을 흰색으로 설정
theme_bw() +
# 그래프 타이틀 설정
ggtitle("교통사고 발생건수와 부상자 수의 상관관계") +
# x축 제목 설정 --> 표시안함을 위해 빈 문자열 설정
xlab("발생건수") +
# y축 제목 설정 --> 표시안함을 위해 빈 문자열 설정
ylab("부상자수") +
# 각 텍스트의 색상, 크기, 각도, 글꼴 설정
theme(plot.title=element_text(family="NanumGothic", color="#0066ff", size=25, face="bold"),
axis.title.x=element_text(family="NanumGothic", color="#999999", size=18, face="bold"),
axis.title.y=element_text(family="NanumGothic", color="#999999", size=18,face="bold", hjust=1),
axis.text.x=element_text(family="NanumGothic", color="#000000", size=16, angle=45),
axis.text.y=element_text(family="NanumGothic", color="#000000", size=16, angle=45))
💻 출력결과
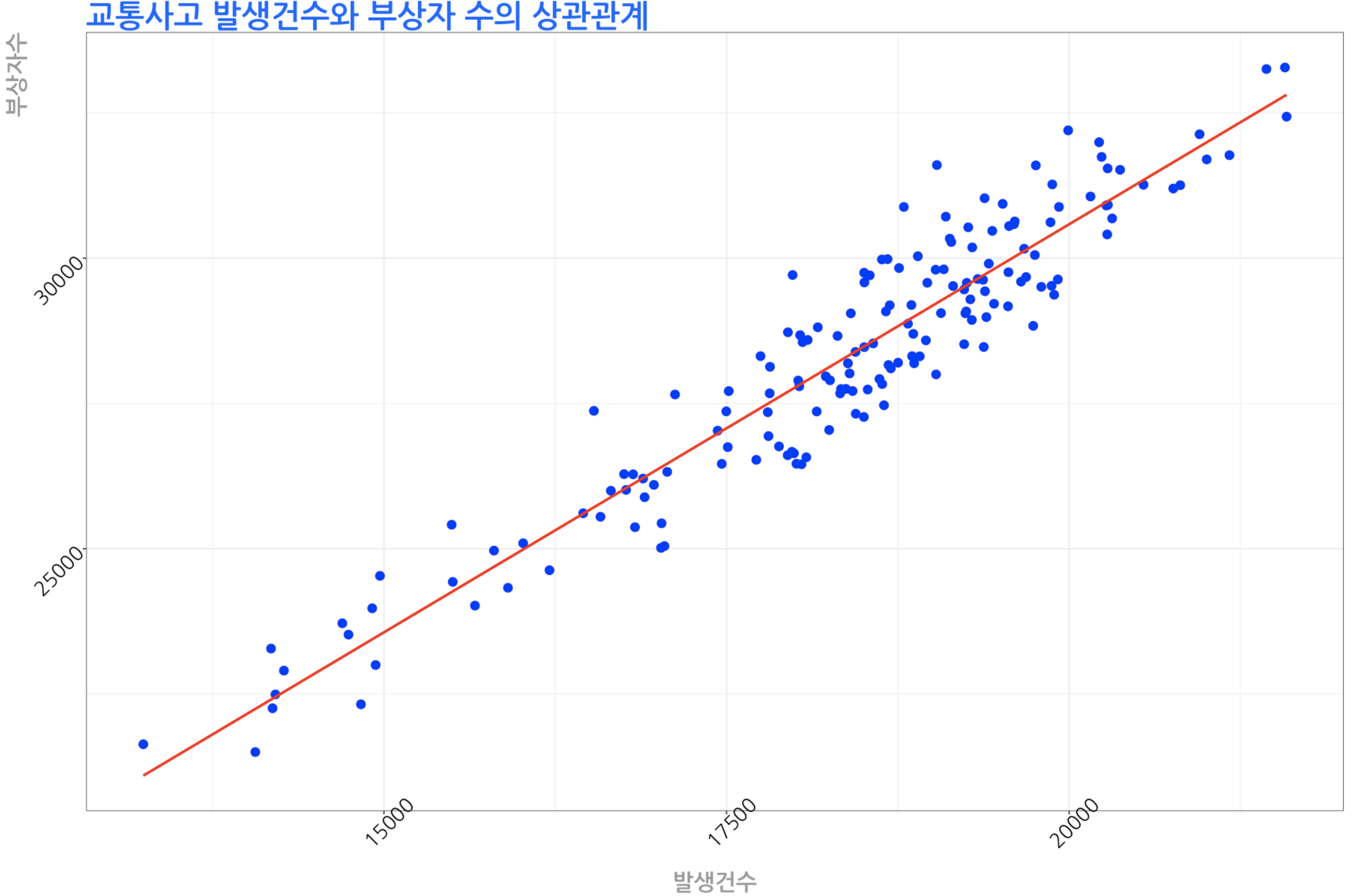
4) 추세선 분석 결과 확인하기
R에서 (단순) 선형 회귀분석을 진행하는 함수는 lm(). 여기에 summary() 함수까지 같이 쓰면 분석 결과를 한 눈에 볼 수 있다.
분석 결과 확인하기
summary(lm(부상자수~발생건수, 교통사고))
💻 출력결과
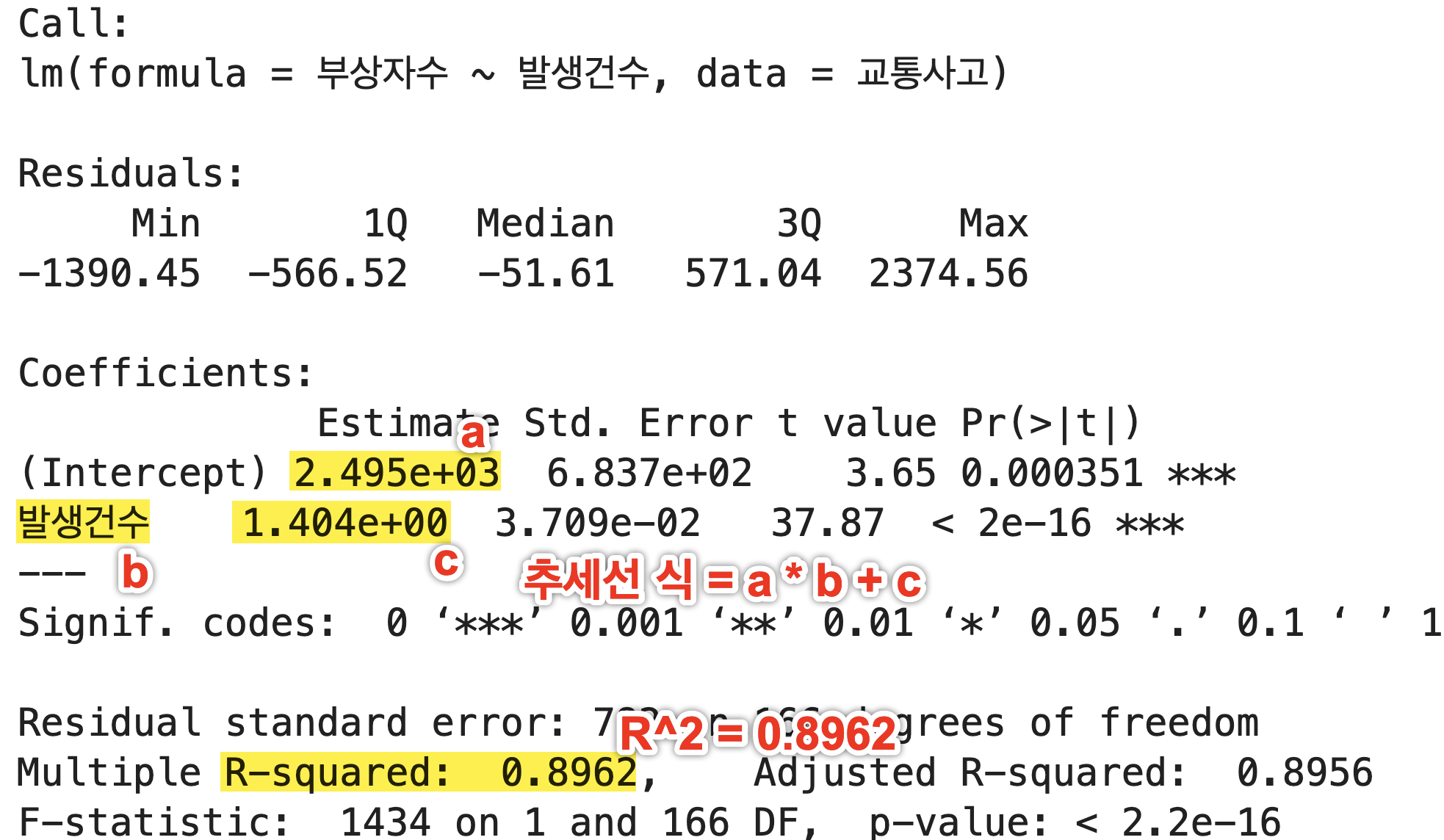
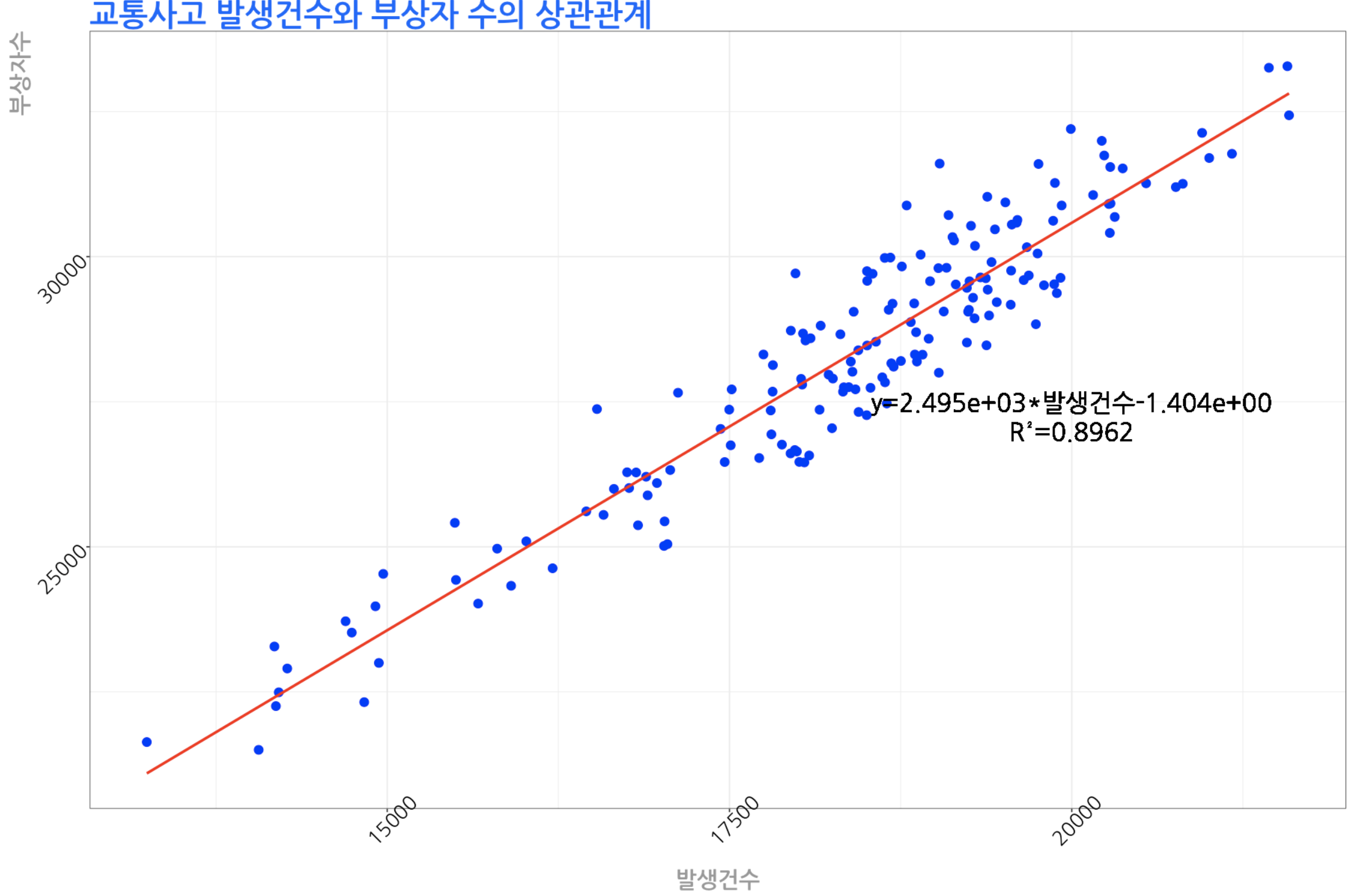
분석 결과에 따른 추세선의 회귀 수식을 그래프에 추가하기
ggplot(data=교통사고, aes(x=발생건수, y=부상자수)) +
geom_point(size=3, colour='blue') +
# 추세선 추가하기
stat_smooth(method = 'lm', se=F, color='#ff0000') +
# 추세선 수식 추가하기
geom_text(x=20000, y=27500, label="y=2.495e+03*발생건수-1.404e+00",
family="NanumGothic", size=7) +
geom_text(x=20000, y=27000, label="R²=0.8962",
family="NanumGothic", size=7) +
# 배경을 흰색으로 설정
theme_bw() +
# 그래프 타이틀 설정
ggtitle("교통사고 발생건수와 부상자 수의 상관관계") +
# x축 제목 설정 --> 표시안함을 위해 빈 문자열 설정
xlab("발생건수") +
# y축 제목 설정 --> 표시안함을 위해 빈 문자열 설정
ylab("부상자수") +
# 각 텍스트의 색상, 크기, 각도, 글꼴 설정
theme(plot.title=element_text(family="NanumGothic", color="#0066ff", size=25, face="bold"),
axis.title.x=element_text(family="NanumGothic", color="#999999", size=18, face="bold"),
axis.title.y=element_text(family="NanumGothic", color="#999999", size=18,face="bold", hjust=1),
axis.text.x=element_text(family="NanumGothic", color="#000000", size=16, angle=45),
axis.text.y=element_text(family="NanumGothic", color="#000000", size=16, angle=45))
💻 출력결과