![[R] 데이터 정제 (1) - 결측치](/images/posts/index-r.png)
[R] 데이터 정제 (1) - 결측치
데이터 정제란 데이터 분석에 앞서 전처리가 완료된 데이터에 대해 빈값(결측치)이나 정상 범위를 벗어난 값(이상치)들을 제거하거나 다른 값으로 대체하는 처리를 말합니다.
#01.결측치
- 비어있는 값 (DB에서의 NULL과 비슷한 의미)
- 현장에서 만들어진 실제 데이터는 수집 과정에서 발생한 오류로 인해 결측치를 포함하고 있는 경우가 많다.
- 결측치가 있으면 통계 처리 함수가 적용되지 않거나 분석 결과가 왜곡되는 문제가 발생한다.
- 결측값을 처리하기 위해서 시간을 많이 사용하는 것은 비효율적이다.
- 결측값 자체의 의미가 있는 경우도 있는데 예를 들면 쇼핑몰 가입자 중 특정 거래 자체가 존재하지 않는 경우와 인구통계학적 데이터(demographic data) 에서 아주 부자이거나 아주 가난한 경우 자신의 정보를 잘 채워 넣지 않기 때문에 가입자의 특성을 유추하여 활용할 수 있다.
- 결측값 처리는 전체 작업속도에 많은 영향을 준다.
1) 단순 대치법(Single Imputation)
Completes Analysis
- 결측값이 존재하는 레코드를 삭제한다.
평균 대치법 (Mean Imputation)
- 관측 또는 실험을 통해 얻어진 데이터의 평균으로 대치한다.
- 비조건부 평균 대치법 : 관측 데이터의 평균으로 대치
- 조건부 평균 대치법 : 회귀분석을 활용한 대치법
단순확률 대치법(Single Stochastic Imputation)
- 평균대치법에서 추정량 표준 오차의 과소 추정문제를 보완하고자 고안된 방법으로 Hotdeck 방법,nearest neighbor 방법 등이 있다.
2) 다중 대치법 (Multiple imputation)
- 단순대치법을 한번하지 않고 m번의 대치를 통해 m개의 가상적 완전 자료를 만드는 방법이다 .
- 1단계 : 대치 (imputation step), 2단계 : 분석 (Analysis step), 3단계 : 결합 (combination step)
3) 결측값 처리 관련 함수
| 함수 | 내용 |
|---|---|
complete.cases() |
데이터내 레코드에 결측값이 있으면 FALSE, 없으면 TRUE 로 반환 |
is.na() |
결측값을 NA로 인식하여 결측값이 있으면 TRUE, 없으면 FALSE 로 반환 |
DMwR 패키지의 centrallmputation() |
NA 값에 가운데 값(central value)으로 대치,숫자는 중위수,요인(factor)은 최빈값으로 대치 |
DMwR 패키지의 knnlmputation() |
NA 값을 k최근 이웃 분류 알고리즘을 사용하여 대치하는 것으로,k개 주변 이웃까지의 거리를 고려하여 가중 평균한 값을 사용 |
#02. 필요한 기본 패키지와 샘플 데이터 준비
패키지 가져오기 (출력결과 없음)
REPO_URL <- "https://cran.seoul.go.kr/"
# `%>%`가 적용되는 기능을 사용하고자 할 경우
if (!require("dplyr")) install.packages("dplyr", repos=REPO_URL)
library(dplyr)
샘플 데이터 준비
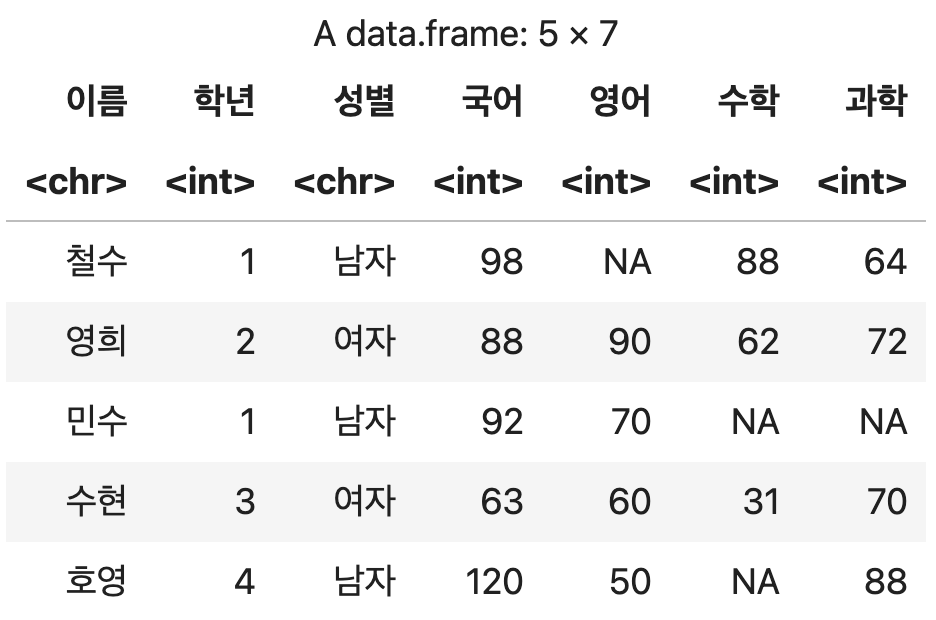
성적표 <- read.csv("http://itpaper.co.kr/demo/r/grade.csv", stringsAsFactors=F, fileEncoding="euc-kr")
성적표
💻 출력결과
#03. 결측치를 확인하는 방법
1) 데이터프레임 전체에 대한 확인
is.na() 함수는 결측치에 대해 TRUE를, 결측치가 아닌 정상 값에 대해 FALSE를 적용한 새로운 DataFrame을 반환한다.
is.na() 함수로 결측치 확인하기
# 결측치 확인 --> 결측치가 맞는 값에 TRUE가 표시된다.
결측치확인 <- is.na(성적표)
결측치확인
💻 출력결과

2) 결측치 빈도수 출력
table() 함수는 DataFrame의 각 열에 대해 값의 종류별로 카운트 한 결과를 산정한 결과를 반환한다.
이를 데이터 빈도수라고 한다.
결측치 빈도수 확인
결측치빈도 <- table(결측치확인)
결측치빈도
💻 출력결과
결측치확인
FALSE TRUE
31 4
3) 각 열별로 결측치 수 확인하기
colSumes() 함수는 DataFrame에서 각 열별로 합산을 수행한다. 이 때 TRUE와 FALSE는 각각 1, 0으로 계산되어 진다.
열별로 결측치 수 확인
colSums(결측치확인)
💻 출력결과
이름 0 학년 0 성별 0 국어 0 영어 1 수학 2 과학 1
2) 특정 변수(컬럼)에 대한 결측치 확인
is.na() 함수에 데이터프레임의 컬럼명까지 함께 전달한다.
결측치에 대해 TRUE를, 결측치가 아닌 정상 값에 대해 FALSE를 적용한 새로운 DataFrame을 반환한다.
수학점수에 대한 결측치 확인
수학점수_결측치 <- is.na(성적표$수학)
수학점수_결측치
💻 출력결과
FALSE FALSE TRUE FALSE TRUE
3) 특정 컬럼에 대한 결측치 빈도수 확인
is.na() 함수의 결과로 반환받은 객체를 table() 함수에 전달하여 TRUE를 1, FALSE를 0으로 처리후합산한다.
수학점수 결측치 빈도수 확인
수학점수_결측치빈도 <- table(수학점수_결측치)
수학점수_결측치빈도
💻 출력결과
수학점수_결측치
FALSE TRUE
3 2
#04. 결측치 소거
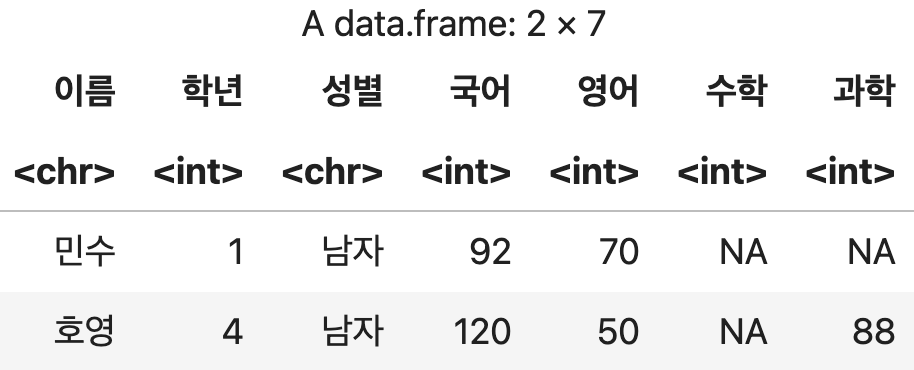
1) 특정 열에 대해 결측치가 포함된 행만 추출하기
filter() 함수를 사용하여 결측치가 포함된 행만 추출한다.
결측치포함 <- 성적표 %>% filter(is.na(수학))
결측치포함
💻 출력결과
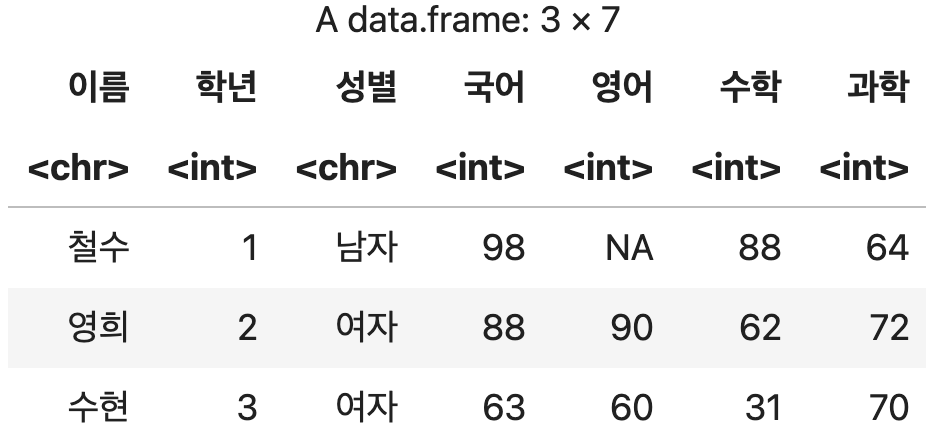
2) 특정 열에 대해 결측치가 포함되지 않은 행만 추출하기
is.na() 함수를 부정하기 위해 !를 적용한다.
결측치없음 <- 성적표 %>% filter(!is.na(수학))
결측치없음
💻 출력결과
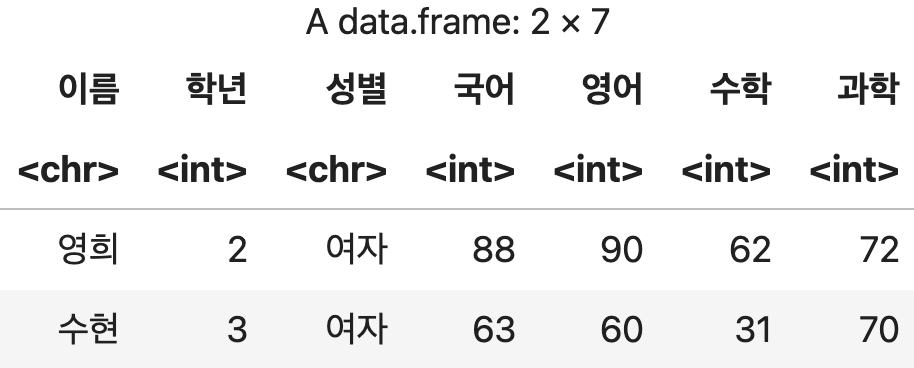
3) 두 개 이상의 열에 대한 결측치 소거
filter 함수에 &로 구분하여 결측치 상태를 지정한다.
결측치가 포함된 행들이 제거된다.
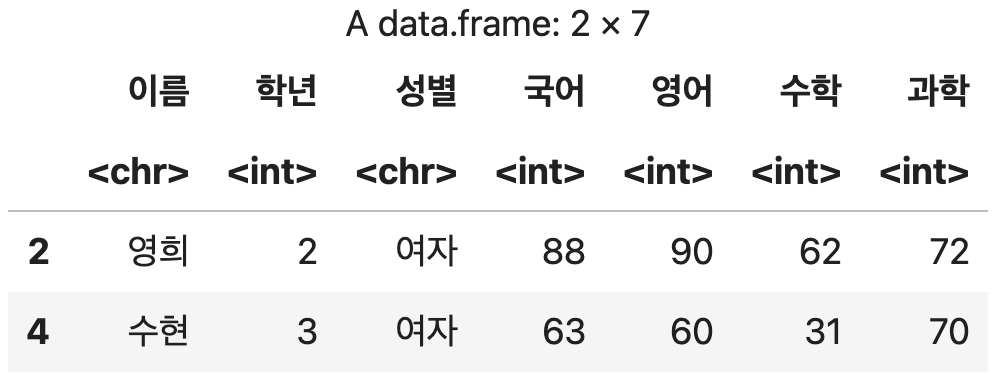
결측치제거 <- 성적표 %>% filter(!is.na(영어) & !is.na(수학) & !is.na(과학))
결측치제거
💻 출력결과
4) 결측치를 전체 데이터프레임에 대해 한번에 제거하기
모든 변수에 결측치 일괄제거
na.omit()은 간단한 장점이 있지만 자칫 분석에 필요한 행까지 손실될 우려가 있다.
예를 들어 분석 목적이 성별에 따른 수학점수 차이를 알아보는 것이라면 na.omit()을 사용했을 때, 국어점수에 결측치가 포함된 철수의 데이터도 삭제된다.
철수는 수학에 대해 결측치가 아니므로 분석이 가능함에도 불구하고 일괄 삭제 기능으로 제거되는 것이다.
따라서 filter()를 이용해 분석에 사용할 수 있는 변수의 결측치만 제거하는 것이 좋다.
일괄제거 <- na.omit(성적표)
일괄제거
💻 출력결과
#05. 결측치 대체
1) 결측치 대체하기 개요
10만건 중에서 1000건 미만의 결측치라면 소거해도 분석 결과에 큰 영향이 없지만 100건 중의 10건이라면 소거법을 적용했을 때 분석 결과에 자칫 큰 영향을 줄 수 있다.
그러므로 결측치 소거보다는 다른 값으로 대체하는 처리를 하는 것이 더욱 바람직하다.
결측치 대체 기준
- 연속형 변수 : 평균이나 중앙값으로 대체
- 수량적 특성에 의한 구분
- 이산형 변수 : 최빈값(가장 많이 등장하는 값)으로 대체
table()함수를 사용하여 빈도를 구할 수 있다.- 범주를 갖는 데이터.
- 범주형 데이터에는 논리적 순서가 없을 수도 있다.
- 성별, 재료 유형, 결제 방법 등
결측치를 대체할 때 고려되어야 하는 사항들
- 결측치의 비율
- 데이터의 분포
- 다른 변수와의 관계가 있는지
2) 결측치 대체하기
a) 각 컬럼별로 결측치 데이터 확인
colSums(is.na(성적표))
💻 출력결과
이름 0 학년 0 성별 0 국어 0 영어 1 수학 2 과학 1
b) 결측치가 존재하는 컬럼에 대한 평균값 얻기
mean() 함수를 사용하면 특정 컬럼에 대한 평균값을 얻을 수 있다. 이 때, na.rm=TRUE 파라미터를 추가하면 결측치를 제외한 평균을 얻을 수 있다.
na.rm 파라미터 미적용시 결측치가 포함된 열은 계산되지 않고
영어평균 <- mean(성적표$영어, na.rm=TRUE)
수학평균 <- mean(성적표$수학, na.rm=TRUE)
과학평균 <- mean(성적표$과학, na.rm=TRUE)
k <- sprintf("영어평균: %f, 수학평균: %f, 과학평균: %f", 영어평균, 수학평균, 과학평균)
k
💻 출력결과
영어평균: 67.500000, 수학평균: 60.333333, 과학평균: 73.500000
c) 결측치가 포함된 컬럼에서 결측치 값을 평균값으로 대체
ifelse() 함수를 사용하여 컬럼의 값이 결측치라면 영어평균을 적용, 그렇지 않다면 원래의 영어점수 적용한다.
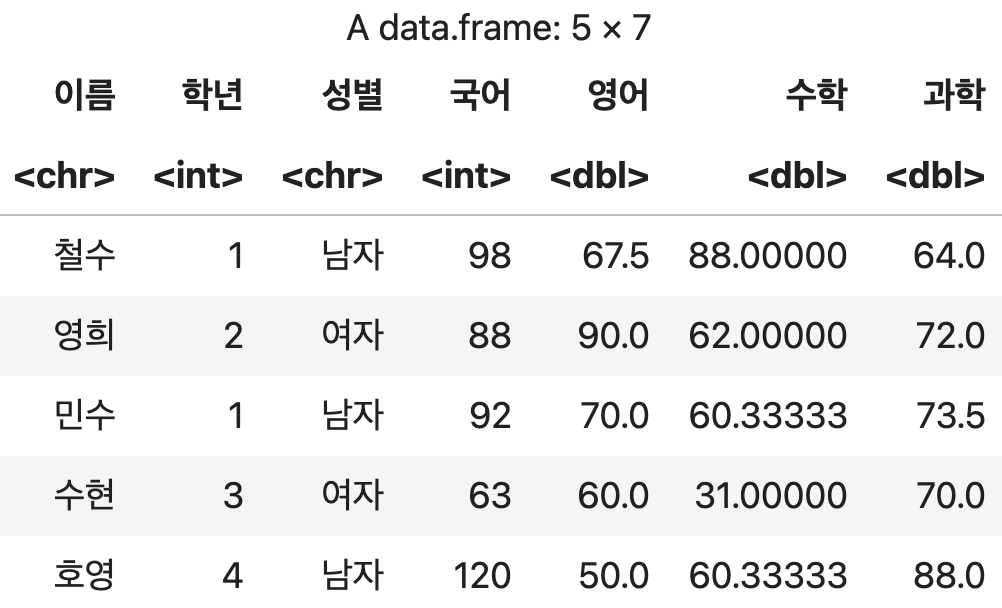
성적표$영어 <- ifelse(is.na(성적표$영어), 영어평균, 성적표$영어)
성적표$수학 <- ifelse(is.na(성적표$수학), 수학평균, 성적표$수학)
성적표$과학 <- ifelse(is.na(성적표$과학), 과학평균, 성적표$과학)
성적표
💻 출력결과
d) 좀 더 간략한 표현
같은 기능을 하는 구문을 좀 더 간략하게 표현하면 아래와 같다.
성적표$영어[is.na(성적표$영어)] <- 영어평균
성적표$수학[is.na(성적표$수학)] <- 수학평균
성적표$과학[is.na(성적표$과학)] <- 과학평균
성적표
💻 출력결과