![[R] 변수의 구간화](/images/posts/index-r.png)
[R] 변수의 구간화
변수를 몇 개의 구간으로 나누어 각 구간별로 몇 개의 데이터가 분포되어 있는지를 확인하는 것은 전체 데이터의 분포를 확인하기 위해 중요한 작업 입니다. 이러한 데이터의 분포를 도수분포라고 합니다.
#01. 도수분포 이해
1) 데이터의 구분
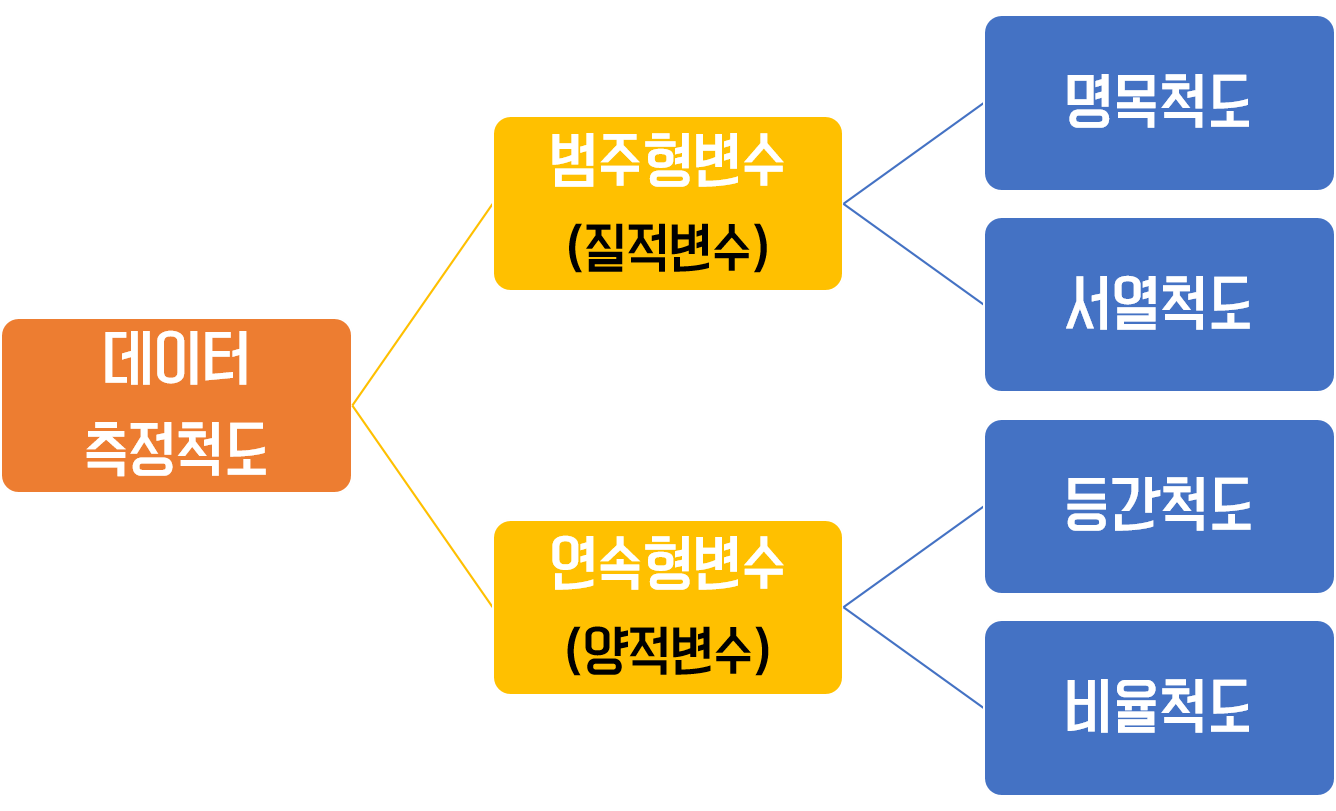
범주형자료(categorical/qualitative)
질적자료로서 명목척도, 서열척도가 이에 해당한다.
| 이름 | 의미 | 예시 |
|---|---|---|
| 명목척도 | - 대상을 특성에 따라 카테고리로 분류하여 기호를 부여한 것 - 측정이 이루어지는 항목들이 상호배타적인 특성만 가진척도 |
성별, 이름, 악기, 번호, 지역 등 |
| 서열척도 | - 대상의 특성들을 구분할 수 있으며 이들 사이의 상대적인 크기를 나타낼 수 있고 서로 간 비교가 가능한 척도 - 명목척도들 중 항목들 간에 서열이나 순위가 존재하는 척도 |
교육정도(중졸, 고졸, 대졸 이상), 선호도 순위, 학점 |
연속형자료(Numerical/quantitative)
양적자료로서 등간척도, 비율척도가 이에 해당한다.
| 이름 | 의미 | 예시 |
|---|---|---|
| 등간척도 | - 상호간의 서열뿐 아니라 인접한 두 변수 값의 차이가 일정한 변수 - 서열척도들 중 항목들 간의 간격이 일정한 척도 |
온도, IQ, 시각, 만족도 ( 매우불만족,약간불만족,보통,약간만족,매우만족) |
| 비율척도 | - 상호간 서열, 크기 차이, 크기의 비교, 특성들 간의 계산까지 가능한 척도 - 등간척도 중 아무 것도 없는 상태를 ‘0’으로 정할 수 있는 척도 |
몸무게, 키, 나이, 길이, 임금 ( 20세 이하,21~30세,31~40세,41~50세, 0이라는 개념은 아직 태어나지 않음을 뜻함) |
2) 도수 분포란?
수집된 자료를 쉽게 이해할 수 있도록 일목요연하게 정리된 표로, 특정 항목 또는 특정 범위에 속하는 빈도수를 나타낸 표
| 용어 | 의미 |
|---|---|
| 계급 (Class) | 자료가 취하는 전체 범위를 몇 개의 소집단(범주,구간)으로 나눈것 |
| 도수/빈도 (Frequency) | 각 계급에 속하는 자료의 수 |
| 상대도수 (Relative Frequency) | 도수를 전체 자료의 수, 즉 전체 도수로 나눈 비율(Proportion,Probability) 상대도수를 모두 합하면, 1 이 됨 |
| 도수분포표 (Frequency Table) | 데이터의 대략적인 분포 형태, 중심위치, 산포 등을 파악하기 위한 데이터정리 방법 계급, 도수, 상대도수, 누적도수 등으로 구성 |
| 잃는 정보 | 자료 그 자체의 수치값 |
| 얻는 정보 | 자료 분포의 특징 (집중성,대칭성 등) |
3) 도수 분포표 예시
연령대가 28, 30, 31, 33, 35, 41, 42가 있다면 특정범위는 20 초과 30 이하, 30초과 40이하, 40초과 50이하 빈도수는 1, 4, 2 합계 7로 표현한다.
절대도수
| 구간 | 도수 |
|---|---|
| 20초과 30이하 | 1 |
| 30초과 40이하 | 4 |
| 40초과 50이하 | 2 |
| 합계 | 7 |
상대도수
| 구간 | 도수 |
|---|---|
| 20초과 30이하 | 14.28 |
| 30초과 40이하 | 57.14 |
| 40초과 50이하 | 28.57 |
| 합계 | 1 |
#02. 샘플 데이터 준비
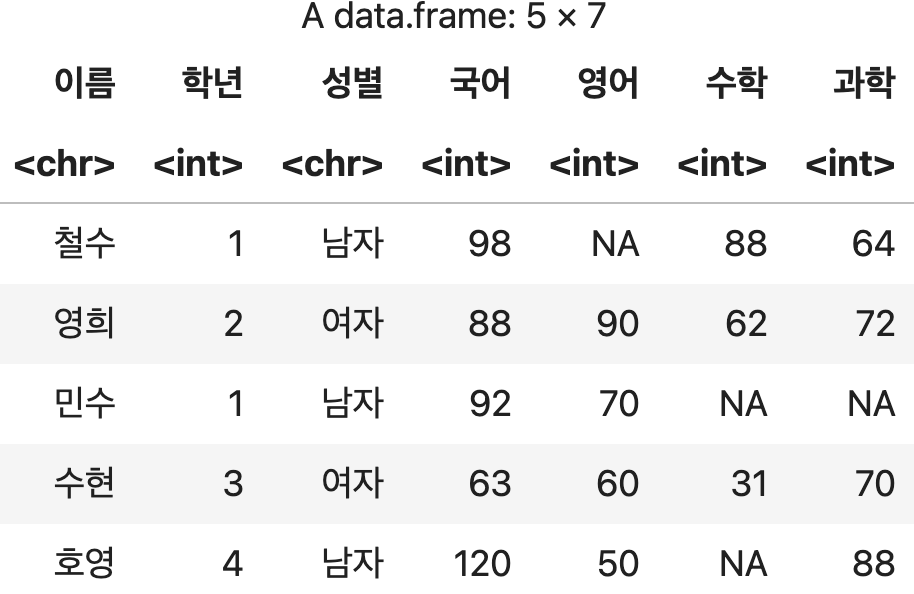
실습용 데이터 준비하기
성적표 <- read.csv("https://data.hossam.kr/r/grade.csv", stringsAsFactors=F, fileEncoding="utf-8")
성적표
💻 출력결과
#03. 도수 분포표 생성하기
table() 함수를 사용하여 도수 분포표 데이터를 얻을 수 있다.
국어점수에 대한 구간별 데이터 수
국어점수분포 <- table(성적표$국어)
국어점수분포
💻 출력결과
63 88 92 98 120
1 1 1 1 1
출력결과에서의 구간별 의미
- 63이상, 88미만 - 1건
- 88이상, 92미만 - 1건
- 92이상, 98미만 - 1건
- 98이상, 120미만 - 1건
- 120이상 - 1건
영어점수에 대한 구간별 데이터 수
영어점수분포 <- table(성적표$영어)
영어점수분포
💻 출력결과
50 60 70 90
1 1 1 1
#03. 교차표
두 변수의 빈도 표를 교차시켜서 교차 분석에 활용한다.
검증하고자 하는 변수가 모두 범주형자료(명목척도, 서열척도) 일 때, 두 변수 간 연관성이 있는지 보기위한 방법
교차분석을 통해서 두 변인 간 교차빈도(교차표)를 볼 수 있고, 교차빈도에 대한 통계적 유의성을 검증하여 두 변인 간 연관성이 있는지에 대하여 알 수 있다.
교차표 생성하기
교차표 <- table(성적표$국어, 성적표$영어)
교차표
💻 출력결과
50 60 70 90
63 0 1 0 0
88 0 0 0 1
92 0 0 1 0
98 0 0 0 0
120 1 0 0 0
#07. 히스토그램
- 자료 값이 가질 수 있는 범위를 몇 개의 구간으로 나누고 각 구간에 해당하는 값의 숫자 혹은 상대적 빈도를 표현하는 그래프.
- 도수분포표에 대한 시각화 결과물
- 가로축이 계급, 세로축이 도수를 나타낸다.
- 표본의 크기가 작으면 데이터 분포의 형상을 잘 표현할 수 없다.
- 그래프의 모양이 치우쳐있거나 봉우리가 여러개 있는 그래프는 비정규 데이터이다.
- 봉유리가 여러개 있는 데이터는 일반적으로 2개 이상의 공정이나 조건에서 데이터가 수집되는 경우 발생한다.
1) hist() 함수를 활용한 히스토그램 작성 과정
- 자료의 갯수와 구간(최대값, 최소값)을 확인한다.
- 자료를 몇 개의 구간으로 나눌지 결정한다.
- 구간은 자료의 개수나 분포에 따라 달라져야 한다.
- 각 구간별로 5개 이상의 값이 들어가도록 하는 것이 좋다.
- 너무 많은 구간을 나누지 않도록 해야 한다. (일반적으로 5~15 사이의 값)
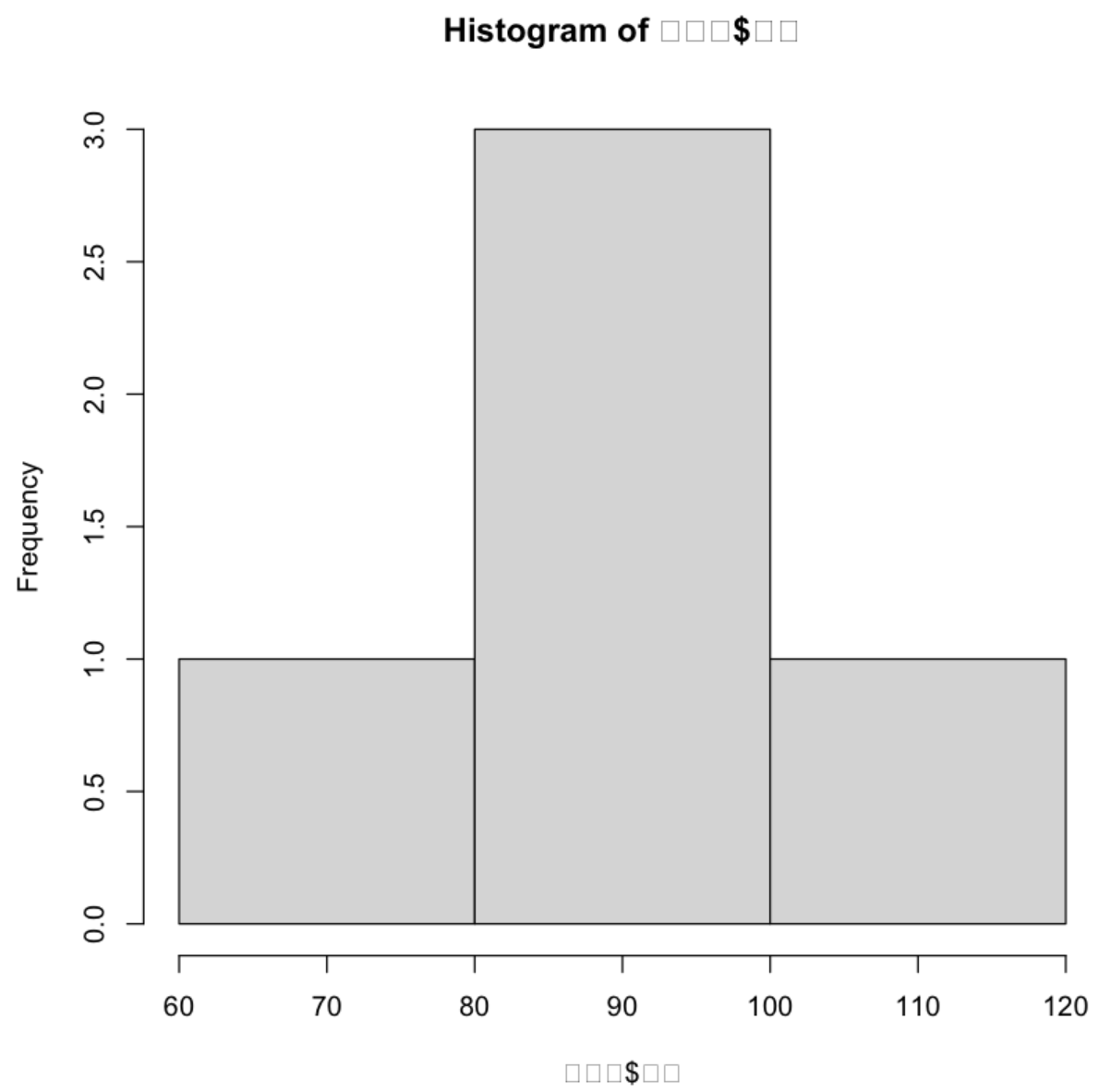
국어점수에 대한 히스토그램 작성하기
hist(성적표$국어)
💻 출력결과
2) jupyter에서의 시각화 옵션 지정하기
a) 그래프 크기 설정
출력될 시각화 결과물의 사이즈를 지정한다. 한번 설정하면 다시 재설정하기 전까지는 이후의 모든 시각화 출력에 영향을 준다.
그래프 크기 설정하기 (출력결과 없음)
options(repr.plot.width=5, repr.plot.height=5)
b) 불필요한 경고 메시지 끄기
한글 처리 과정에서 표시되는 불필요한 경고 메시지가 표시되지 않도록 설정한다.
경고 메시지 끄기(출력결과 없음)
options(warn=-1)
3) 한글 처리하기
a) 한글을 사용할 수 있는 폰트 확인을 위한 패키지 설치 및 로드
REPO_URL <- "https://cran.seoul.go.kr/"
if (!require("extrafont")) {
install.packages("extrafont", repos=REPO_URL)
}
library(extrafont)
b) NanumGothic이라는 단어를 포함하는 이름을 갖는 폰트 설치하기
운영체제에 설치된 글꼴들을 R 자체적으로 관리하는 폰트 디렉토리로 복사한다.
나눔고딕이 설치되어 있지 않은 경우 네이버에서 검색후 다운로드 가능함.
font_import(pattern = "NanumGothic")
💻 출력결과
실행하는데 수 분 이상 소요된다.
Importing fonts may take a few minutes, depending on the number of fonts and the speed of the system.
Continue? [y/n] y
Scanning ttf files in /Library/Fonts/, /System/Library/Fonts, ~/Library/Fonts/ ...
Extracting .afm files from .ttf files...
/Users/leekh/Library/Fonts/NanumGothic.ttf : NanumGothic already registered in fonts database. Skipping.
/Users/leekh/Library/Fonts/NanumGothicBold.ttf : NanumGothicBold already registered in fonts database. Skipping.
/Users/leekh/Library/Fonts/NanumGothicExtraBold.ttf : NanumGothicExtraBold already registered in fonts database. Skipping.
/Users/leekh/Library/Fonts/NanumGothicLight.ttf : NanumGothicLight already registered in fonts database. Skipping.
Found FontName for 0 fonts.
Scanning afm files in /usr/local/lib/R/3.6/site-library/extrafontdb/metrics
c) 설치된 폰트 목록 확인
fonttable() 함수를 통해 반환받는 DataFrame에서 FamilyName 컬럼을 확인하면 R 소스코드에 적용해야 할 폰트 이름을 확인할 수 있다.
출력결과는 시스템에 설치되어 있는 글꼴의 상태에 따라 다를 수 있다.
- 글꼴 목록 확인하기
ftable <- fonttable()
ftable$FamilyName
💻 출력결과
'NanumGothic''NanumGothicCoding''NanumGothicCoding'
d) 설치된 폰트들 로드하기
# mac의 경우 `device="win"` 생략
loadfonts(device="win")
💻 출력결과
Registering font with R using pdfFonts(): NanumGothic
Registering font with R using pdfFonts(): NanumGothicCoding
e) 히스토그램 작성시 사용할 글꼴 지정하기
par() 함수를 사용하여 사용할 글꼴 이름을 지정해 준다.
# 글꼴 지정
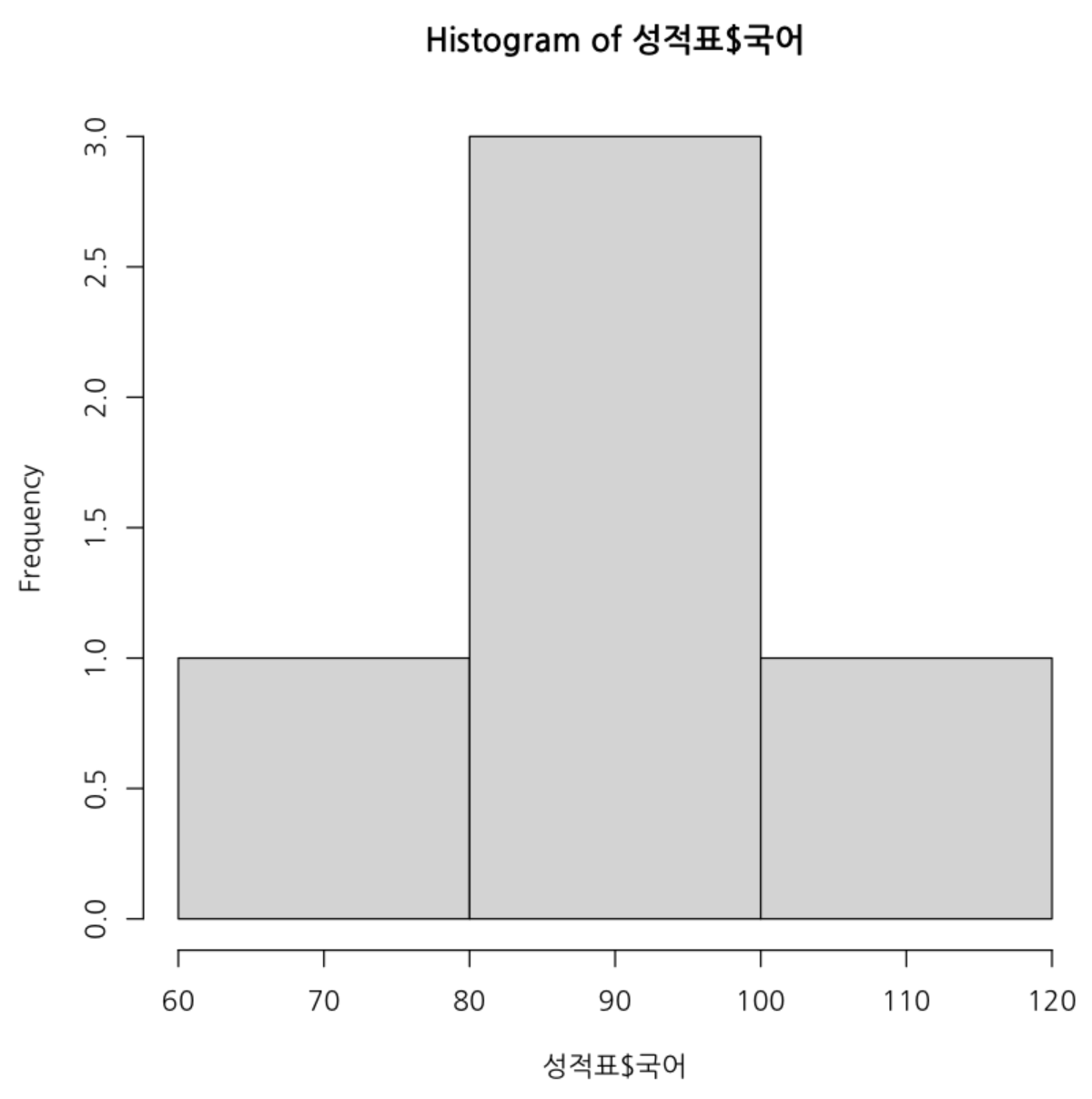
par(family = "NanumGothic")
# 히스토그램 생성
hist(성적표$국어)
💻 출력결과
f) 히스토그램 함수의 파라미터
| 파라미터 | 설명 |
|---|---|
| labels | 수치값 표시 여부. TRUE / FALSE |
| main | 메인 타이틀 |
| xlab | x축 라벨 |
| ylab | y축 라벨 |
| breaks | 계급 구간 수에 대한 숫자값 혹은 알고리즘 이름 1. 계급 구간의 수. 2. breakpoint를 구하는 함수. - nclass.Sturges, nclass.scott, nclass.FD 3. 계급 구간의 수를 구하는 알고리즘 문자열. - “Sturges”,”Scott”,”FD”,”freedmandiaconis” |
| freq | - TRUE일 때, y축의 단위는 frequencies(도수), (default) - FALSE일 때, probabilities(상대도수). |
| density | 막대 내부 빗금의 밀도. (default=NULL) |
| angle | 막대 내부 빗금의 기울기. (default=45) |
| col | 막대 내부 색. |
| border | 막대 테두리 색. |
| plot | - TRUE일 때, 히스토그램을 출력(default). - FALSE일 때 자료값들을 리스트로 반환. |
옵션을 적용한 히스토그램
# 한글 글꼴 적용
par(family = "NanumGothic")
# 그래프의 가로, 세로 사이즈 적용
options(repr.plot.width=5, repr.plot.height=6.5)
# 히스토그램 그리기
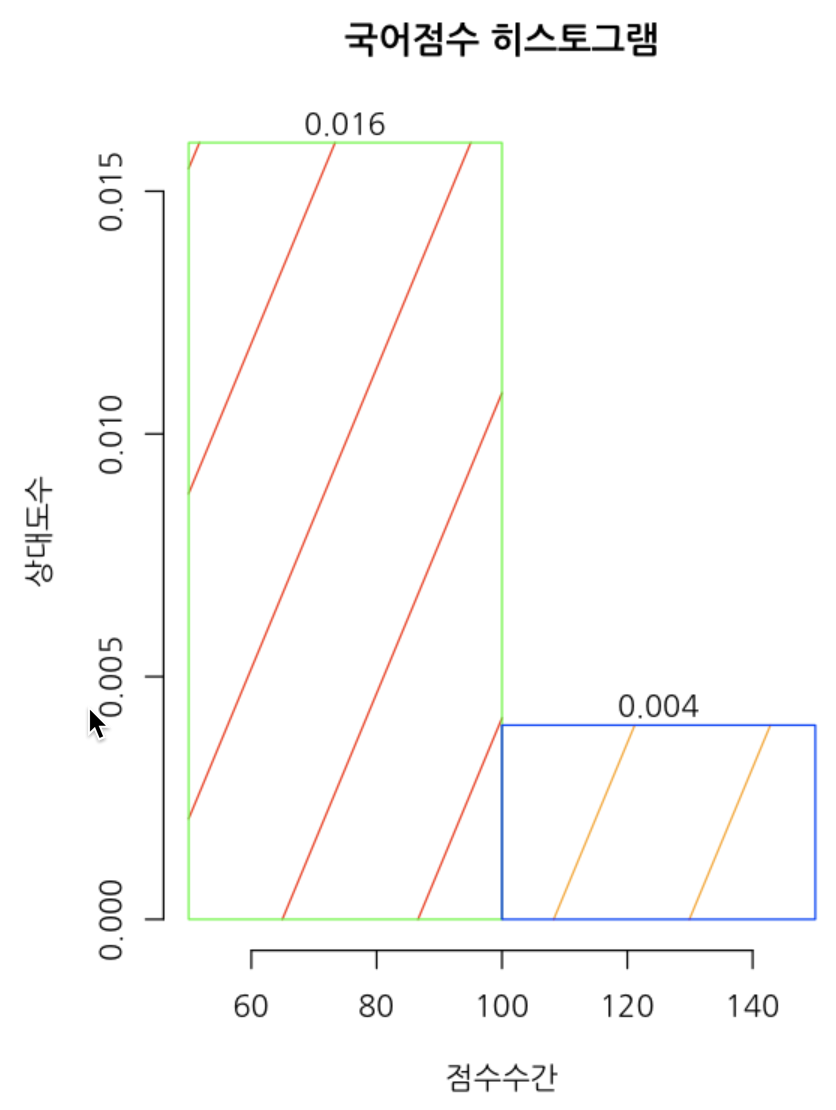
hist(성적표$국어,
labels=TRUE,
main='국어점수 히스토그램',
xlab='점수수간',
ylab='상대도수',
breaks=2,
freq=FALSE,
density=1,
angle=60,
col=c('red','orange'),
border=c('green', 'blue'),
plot=TRUE)
💻 출력결과
g) 히스토그램의 자료값 반환받기
plot 파라미터를 FALSE로 지정하여 사용한다.
이 때 breaks를 제외한 다른 파라미터는 사용되지 않기 때문에 hist 함수에 설정할 경우 경고 메시지가 표시된다.
| 이름 | 태그 |
|---|---|
| breaks | 계급(구간) |
| counts | 각 계급별 도수 (데이터 수) |
| density | 각 계급별 상대도수 (확률밀도) |
| mids | 데이터 구간 (최소값~최대값) |
| xname | 데이터 이름 |
히스토그램 함수의 리턴값 확인
k <- hist(성적표$국어, breaks=2, plot=FALSE)
k
💻 출력결과
$breaks
[1] 50 100 150
$counts
[1] 4 1
$density
[1] 0.016 0.004
$mids
[1] 75 125
$xname
[1] "성적표$국어"
$equidist
[1] TRUE
attr(,"class")
[1] "histogram"
#08. Wages 데이터 셋 히스토그램
ISLR 패키지에 내장된 교육수준, 임금수준, 직종수준 등에 대한 조사 데이터
1) 데이터셋 불러오기
패키지 설치 및 로드
REPO_URL <- "https://cran.seoul.go.kr/"
if (!require("ISLR")) { install.packages("ISLR", repos=REPO_URL) }
if (!require("ggplot2")) { install.packages("ggplot2", repos=REPO_URL) }
library(ISLR)
library(ggplot2)
데이터 확인
head(Wage)
💻 출력결과
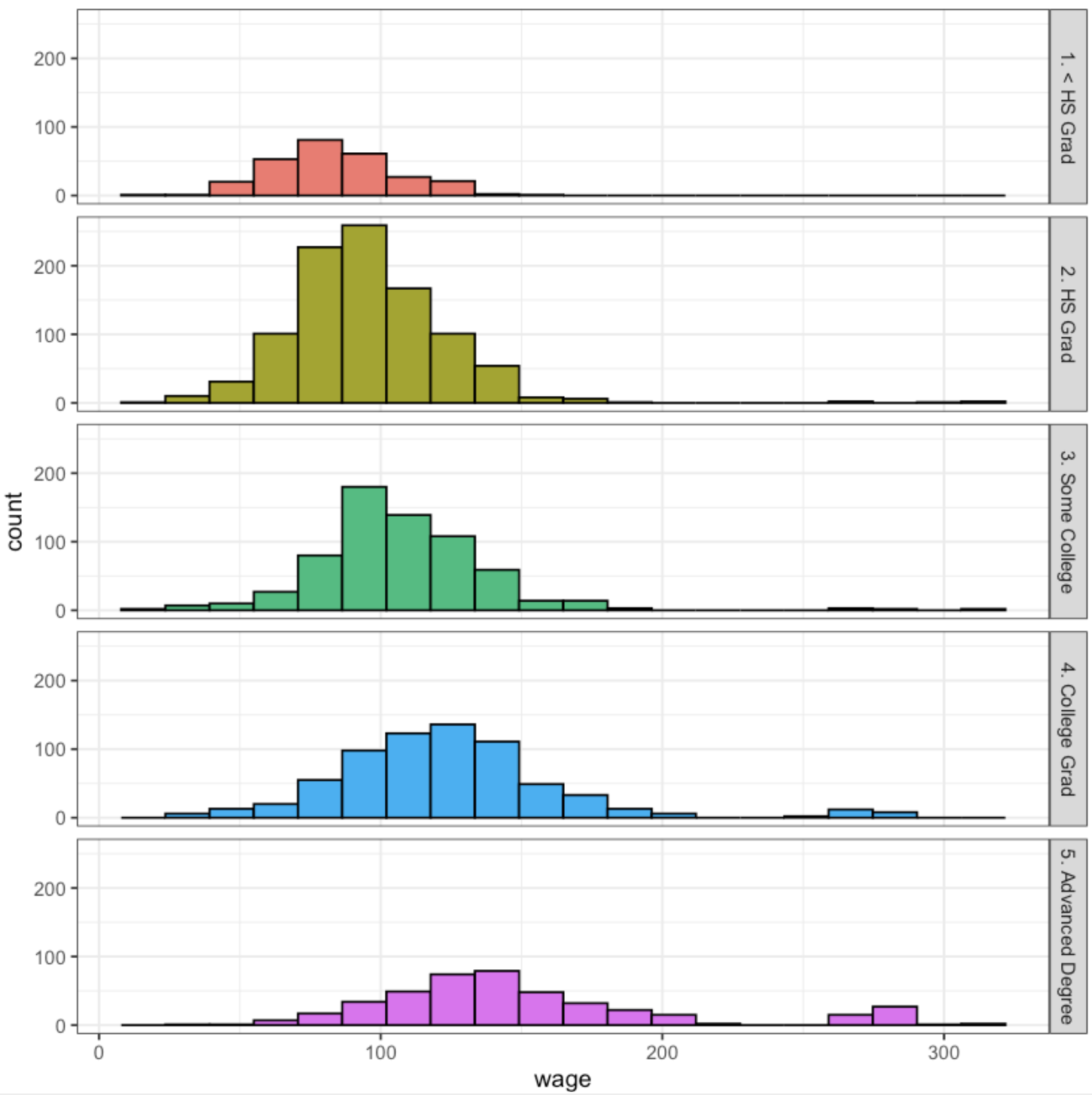
2) 근로자의 교육 수준에 따른 임금 분포
히스토그램 그리기
ggplot(Wage, aes(x=wage, fill=education)) +
geom_histogram(col="black", bins=20) + theme_bw() +
facet_grid(education ~ .) + xlab('wage') +
theme(legend.position = "none")
💻 출력결과
히스토그램 해석
- 각 학력 수준에 따라 임금의 분포를 나타낸다.
- 학력 수준이 높아질수록 임금은 높아지는 경향이 있다.
- 각 막대의 높이는 해당 임금을 받는 근로자의 수를 나타낸다.
- 임금 수준은 x축이다.
- Advanced Degree 그룹의 임금 분포는 쌍봉이다.