![[R] 데이터 마트 구성](/images/posts/index-r.png)
[R] 데이터 마트 구성
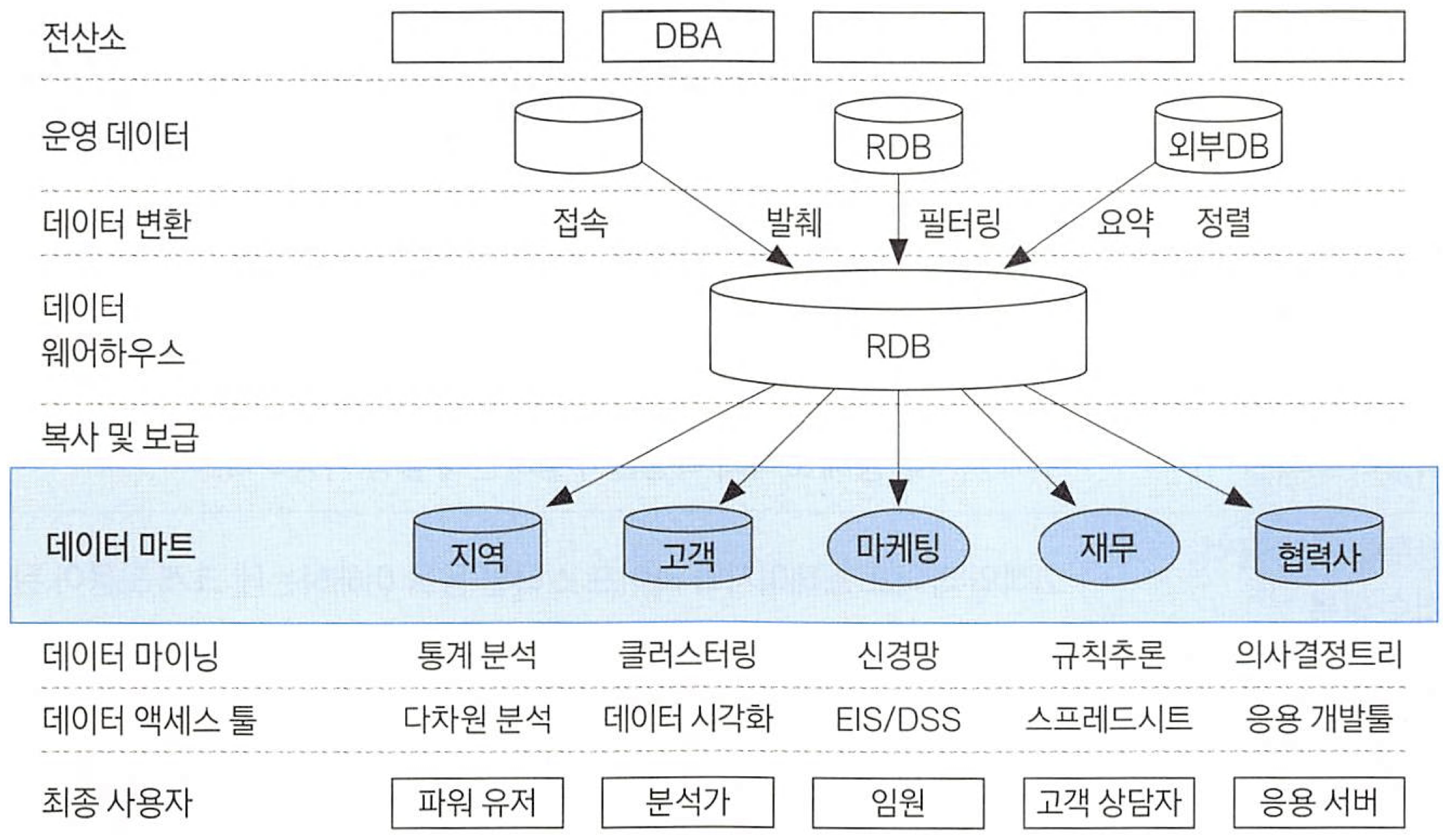
데이터 마트(Data Mart, DM)는 데이터 웨어 하우스(Data Warehouse, DW)와 사용자 사이의 중간층으로서 하나의 주제 또는 하나의 부서 중심의 DataFrame입니다. 대부분 DW로부터 복제되지만 분석가가 자체적으로 수집할 수 도 있습니다. 대부분 관계형 데이터베이스나 다차원 데이터베이스를 이용하고 구축합니다.
고객과 관련된 데이터마트를 구축한다면 CRM관련 핵심 업무에 활용될 수 있습니다. 그러므로 DM을 어떻게 구축하는지에 따라 분석 효과의 차이가 매우 큽니다.
#01. 데이터마트 개요
- DW와 사용자 사이의 중간층
- 하나의 주제 또는 하나의 부서 중심의 DW
- 대부분 DW로부터 복제됨
- 자체적으로 수집될 수도 있음.
- 관계형 데이터베이스나 다차원 데이테이스를 이용하여 구축
- CRM 관련 핵심 업무 - 고객 데이터 마트 구축
- DM을 어떻게 구축하는지에 따라 분석 효과 차이 큼
#02. 요약변수
1) 정의
- 수집된 정보를 분석에 맞게 종합한 변수
- 데이터마트에서 가장 기본적인 변수
- 분석을 위해 만들어짐 - 총구매금액,금액,횟수,구매여부 등의 분석을 위해 만들어 짐
- 재활용성 높음
- 합계, 횟수 등의 간단한 구조이므로 자동화 구축 가능
- 일정 수치 이상이면 기준값의 해석이 애매할 수 있으므로 연속성 변수를 그룹핑해 사용하는 것이 좋다.
요약변수 예시
| 종류 | 예시 |
|---|---|
| 기간별 구매 금액, 횟수 여부 | 고객의 구매 패턴 |
| 위클리 쇼퍼 | 구매 시기를 통해 고객의 특성 추정 |
| 상품 구매 금액, 회수 여부 | 고객의 라이프 스테이지와 라이프 스타일 등 이해 |
| 상품별 구매 순서 | 고객의 이해, 해석력 |
| 유통 채널별 구매 금액 | 온,오프라인 사용 고객에게 모두 사용하도록 유도하는데 활용 |
| 단어 빈도 | 텍스트 자료에서 단어들의 출현 빈도 데이터화 |
| 초기 행동 변수 | 고객 가입 또는 첫 거래 초기 1개월간 거래 패턴 1년후 어떤 행동을 보일지에 대한 평가 지표 |
| 트렌드 변수 | 추이값을 나타냄 |
| 결측값, 이상값 | 무리해서 처리할 경우 위험도 높음 데이터의 내용을 파악하여 처리 |
| 연속성 변수의 구간화 | 분석 후 적용 단계를 고려한 분석을 위해 연령, 비용 등을 구간화 처리 의미 있는 구간으로 나눔 |
2) 패키지 로드 및 샘플 데이터 준비
패키지 로드하기
REPO_URL = "https://cran.seoul.go.kr/"
if (!require(dplyr)) install.packages("dplyr", repos=REPO_URL)
library(dplyr)
샘플 데이터 준비하기
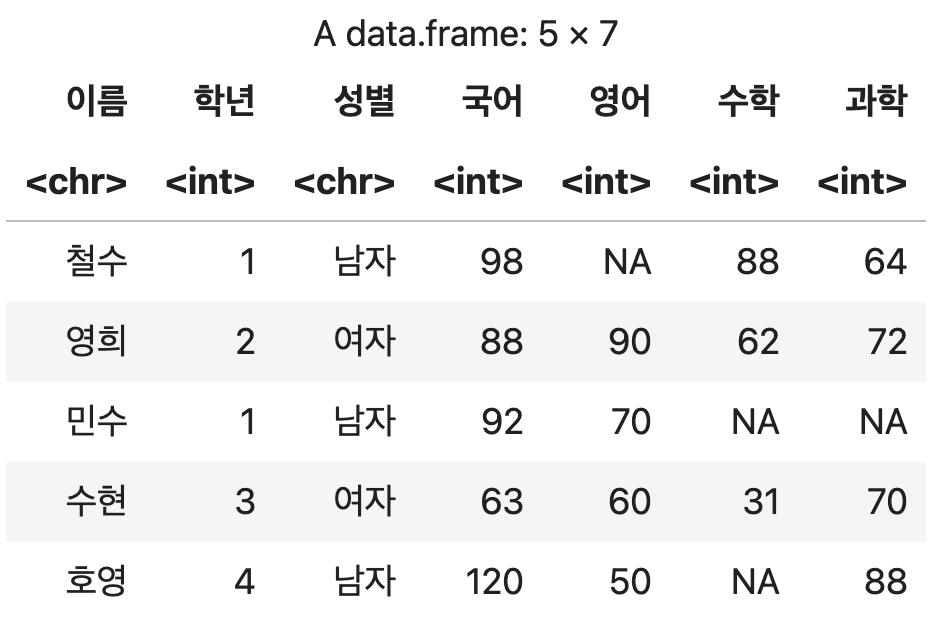
성적표 <- read.csv("https://data.hossam.kr/r/grade.csv", stringsAsFactors=F, fileEncoding="euc-kr")
성적표
💻 출력결과
3) 각각의 열에 대한 집계
데이터 프레임에서 summarise() 함수를 통해 집계함수를 사용하면 열단위(세로방향)에 대해 수행된다.
단, 결측치(NA)가 포함된 열은 연산이 불가능하다.
사용 가능한 대표적인 집계 함수
- mean(컬럼이름) : 평균
- sd(컬럼이름) : 표준편차
- sum(컬럼이름) : 합계
- median(컬럼이름) : 중앙값
- min(컬럼이름) : 최소값
- max(컬럼이름) : 최대값
- n(컬럼이름) : 빈도
전체 합계
영어, 수학, 과학의 경우 결측치가 포함되어 있기 때문에 집계가 수행되지 않는다.
%>% 연산자는 dplry 패키지에 의해서 사용 가능한 기능으로 여러 개의 함수를 연속적으로 사용할 수 있도록 한다.
과목별 총점 구하기
df <- 성적표 %>% summarise(국어총점=sum(국어), 영어총점=sum(영어), 수학총점=sum(수학), 과학총점=sum(과학))
df
💻 출력결과

결측치를 제외한 집계 수행
집계함수에대해 na.rm=TRUE 파라미터를 설정한다.
결측치를 제외한 과목별 합계
df <- 성적표 %>% summarise(
국어평균=mean(국어, na.rm=TRUE),
영어평균=mean(영어, na.rm=TRUE),
수학평균=mean(수학, na.rm=TRUE),
과학평균=mean(과학, na.rm=TRUE))
df
💻 출력결과

2) 각각의 행에 대한 집계
mutate() 함수와 집계함수를 함께 사용하여 파생변수를 추가하는 형태로 접근할 수 있다.
사용 가능한 대표적인 집계 함수
rowMeans(데이터프레임[시작인덱스:끝인덱스]): 평균rowSums(데이터프레임[시작인덱스:끝인덱스]): 합계
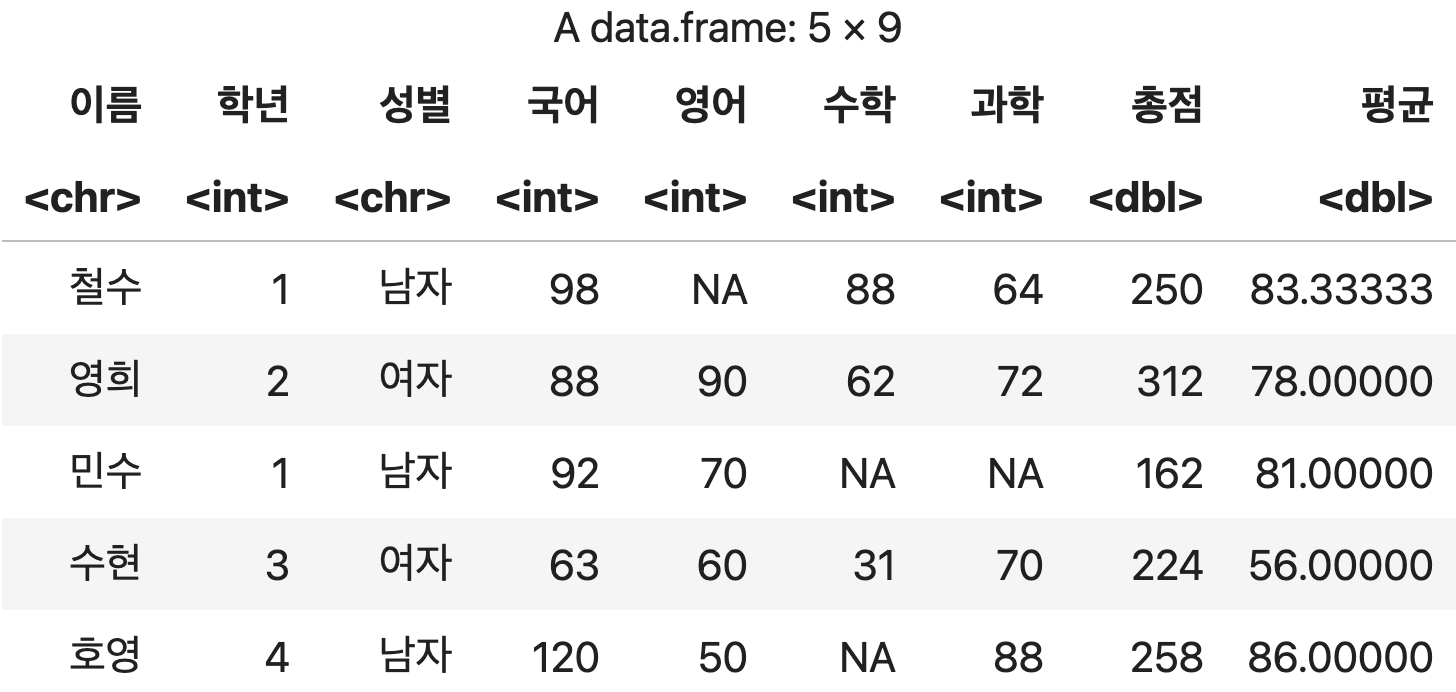
학생별 총점과 평균 구하기
df <- 성적표 %>%
mutate(총점=rowSums(성적표[4:7], na.rm=TRUE),
평균=rowMeans(성적표[4:7], na.rm=TRUE))
df
💻 출력결과
3) 집단별로 나누기
- 동일한 값을 갖는 데이터들끼리 그룹으로 묶고, 그 이외의 다른 데이터들에게 집계를 수행하는 형태.
- SQL의 group by절과 같은 기능.
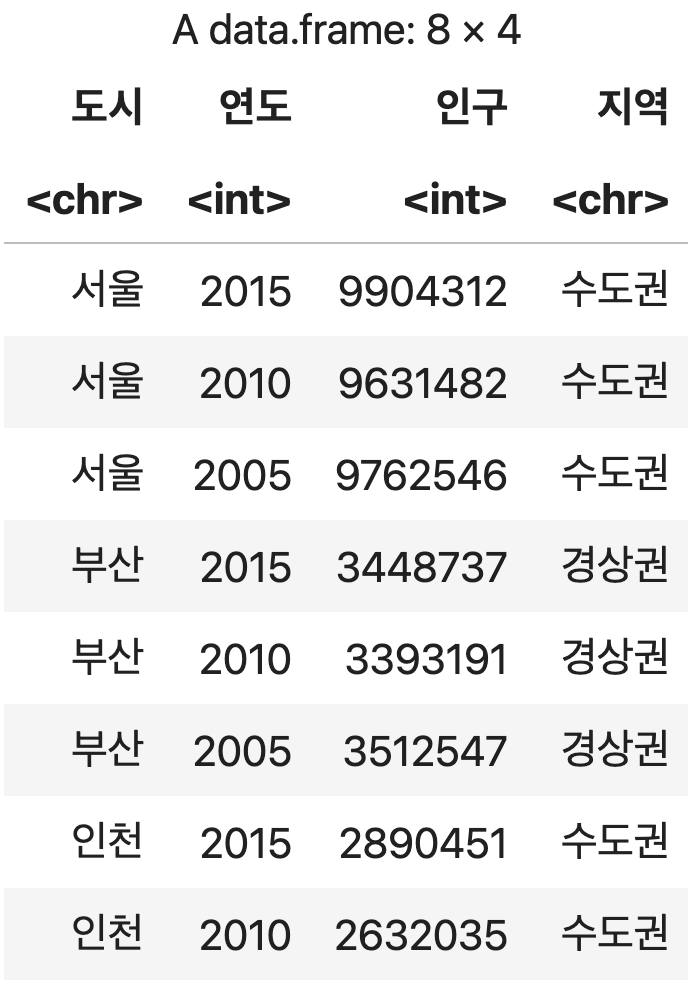
샘플 데이터 가져오기
인구조사 <- read.csv("https://data.hossam.kr/r/city_people.csv", stringsAsFactors=F, fileEncoding="utf-8")
인구조사
💻 출력결과
dplyr 패키지의 chain 기능 활용하기
%>%연산자를 연속적으로 사용하여 여러 개의 함수를 연결해서 사용할 수 있다.- 추가된 변수는 다른 함수에서 즉시 연결해서 사용 가능하다.
하나의 컬럼을 집단별로 나누고 그룹분석 수행하기
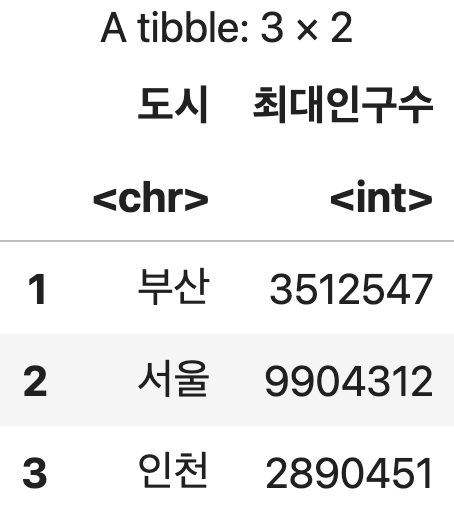
15년간의 도시별 최대 인구수
df <- 인구조사 %>%
group_by(도시) %>%
summarise(최대인구수=max(인구, na.rm=TRUE))
df
💻 출력결과
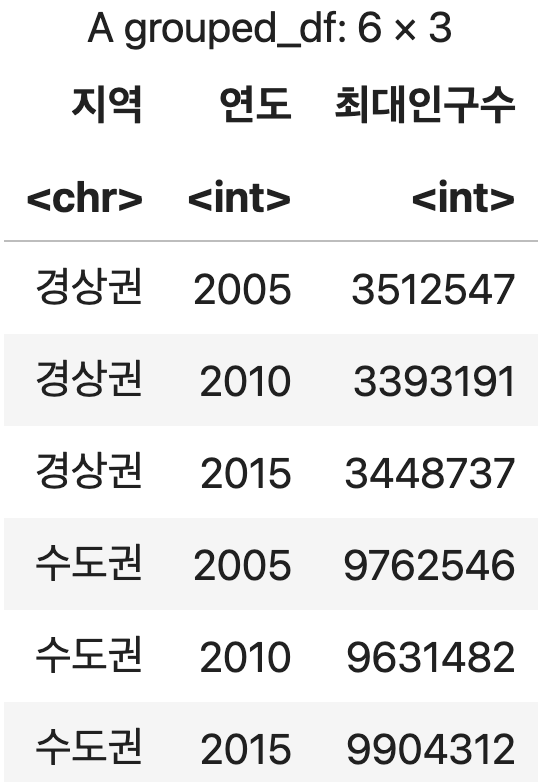
두 개 이상의 컬럼을 집단별로 나누고 그룹분석 수행하기
각 지역별로 5년단위 최대 인구수
df <- 인구조사 %>%
group_by(지역, 연도) %>%
summarise(최대인구수=max(인구, na.rm=TRUE), .groups='keep')
df
💻 출력결과
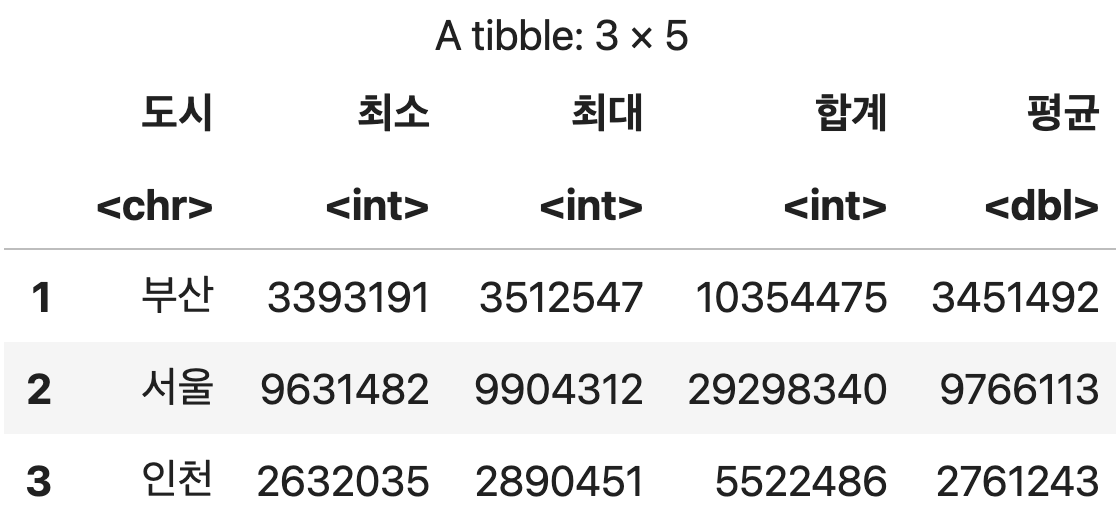
하나의 컬럼에 대해 여러 개의 집계함수 동시 사용
인구수에 대한 최소, 최대, 합계, 평균
도시인구 <- 인구조사 %>%
group_by(도시) %>%
summarise(최소=min(인구, na.rm=TRUE),
최대=max(인구, na.rm=TRUE),
합계=sum(인구, na.rm=TRUE),
평균=mean(인구, na.rm=TRUE))
도시인구
💻 출력결과
#03. 파생변수
💡 파생 변수에 대해서는 데이터 전처리 단원에서 예제 코드를 제시합니다.
- 특정 조건을 만족하거나 특정 함수에 의해 값을 만들어 의미를 부여한 변수
- 주관적 - 논리적 타당성을 갖추어야 함
- 세분화, 고객행동, 캠페인 반응 예측등에 활용
- 특정 상황에서만 유의미하지 않게 대표성을 나타나게 해야 함
| 종류 | 설명 |
|---|---|
| 근무시간 구매지수 | |
| 주 구매 매장 변수 | |
| 주 활동 지역 변수 | |
| 주 구매상품 변수 | 상품 추천에 활용 |
| 구매상품 다양성 변수 | 다양한 상품이나 브랜드 등을 구매하는 성향 |
| 선호하는 가격대 변수 | |
| 라이프 스테이지 변수 | 고객이 속한 라이프 스테이지 예측, 행동 이해, 니즈와 가치 파악에 활용 |
| 라이프 스타일 변수 | |
| 행사민감 변수 | |
| 휴면가망 변수 | |
| 최대가치 변수 | |
| 최적 통화 시간 |
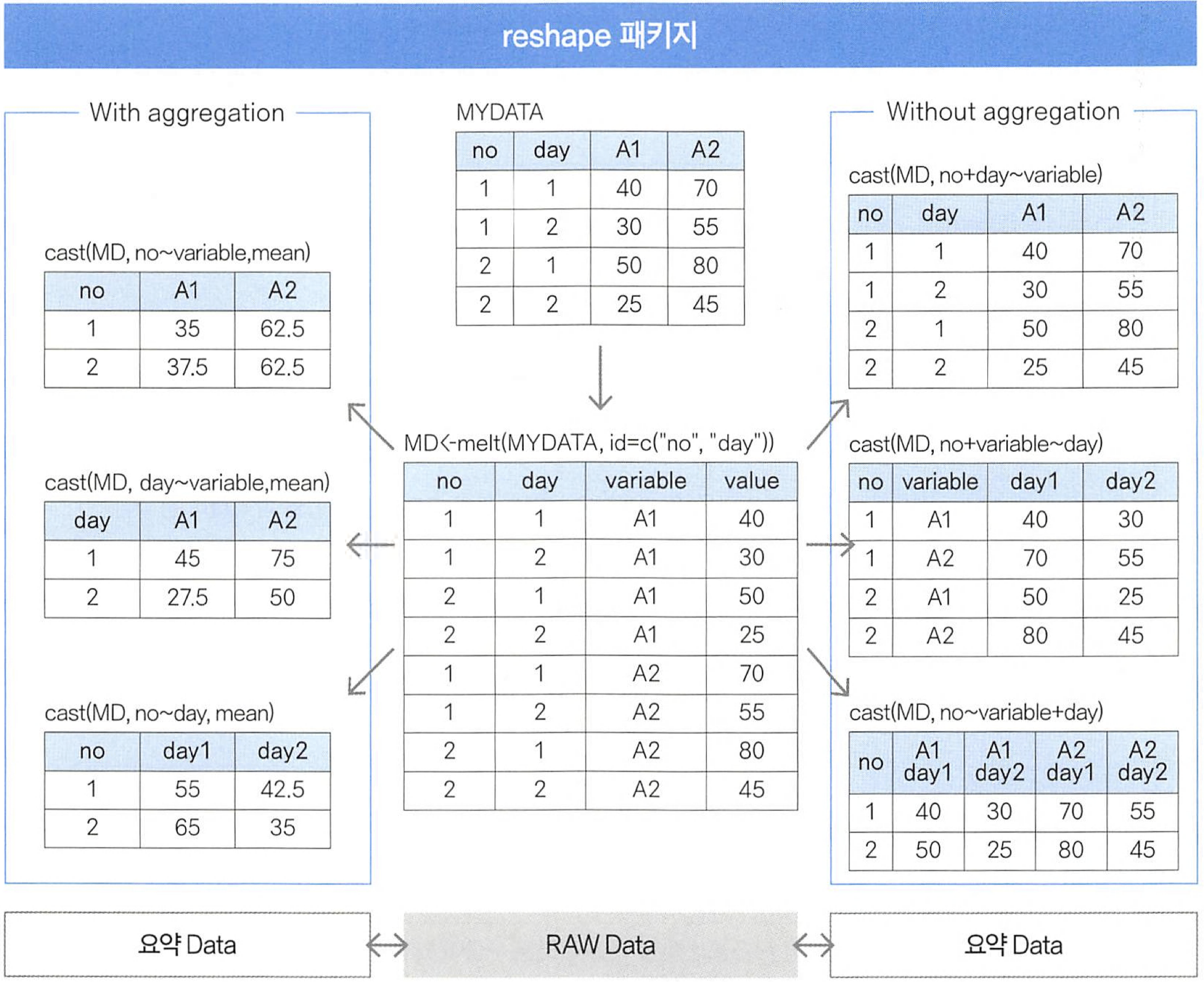
#04. reshape 활용
1) 필요한 기본 패키지와 샘플 데이터 준비
패키지 가져오기 (출력결과 없음)
REPO_URL <- "https://cran.seoul.go.kr/"
if (!require("reshape")) install.packages("reshape", repos=REPO_URL)
library(reshape)
샘플 데이터 준비
no <- c(1,1,2,2)
id <- c('lee','kim','kang','nam')
height <- c(180, 170, 168, 173)
weight <- c(70, 85, 80, 75)
df <- data.frame(no, id, height, weight)
df
💻 출력결과
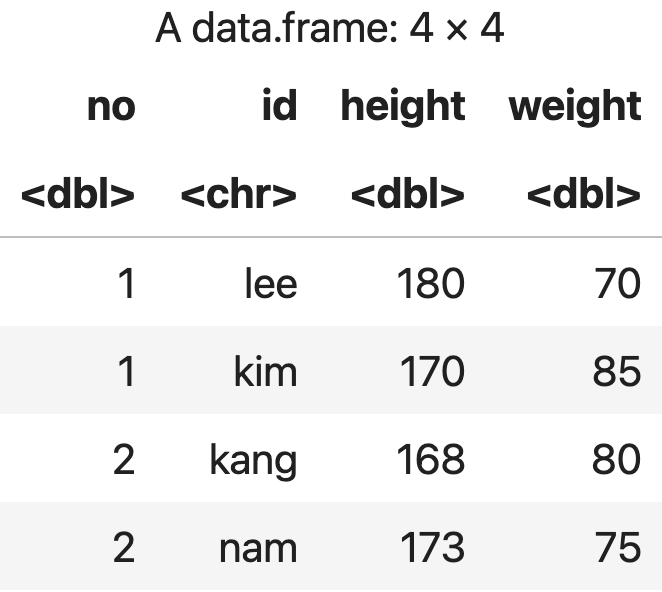
2) melt() 함수로 데이터 분할하기
melt( ) 함수는 식별자id, 측정 변수variable, 측정치value 형태로 데이터를 재구성하는 함수다.
DM을 분할하여 원데이터로 만듦
번호와 아이디에 따른 데이터 재구성
m_data <- melt(df, id=c('no','id'))
m_data
💻 출력결과
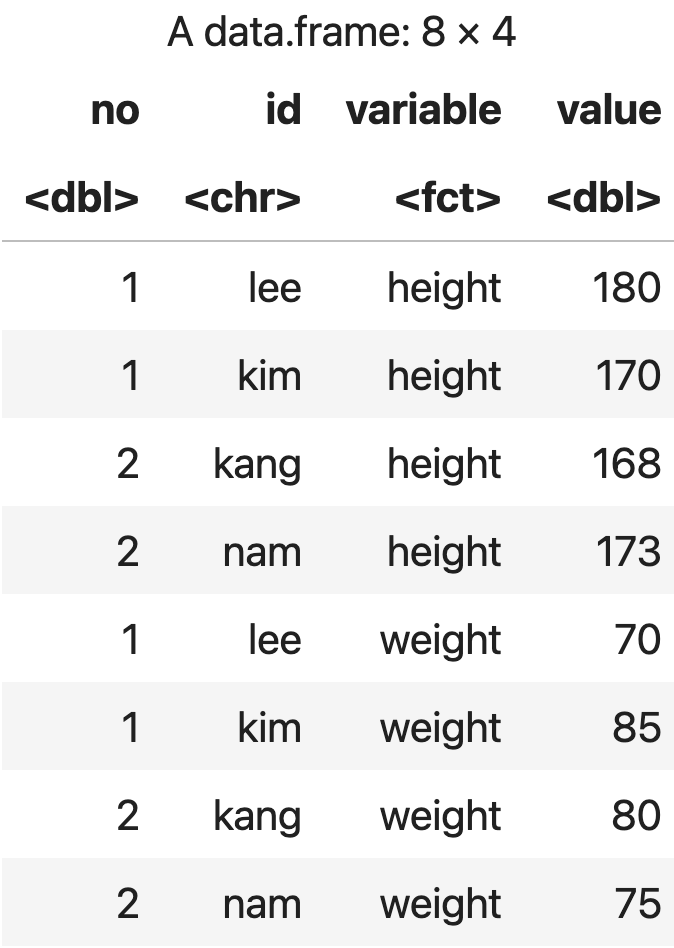
3) cast() 함수로 데이터 조합하기
cast( ) 함수를 사용하면 melt 된 데이터를 원하는대로 조합할 수 있다.
요약 형태로 만듦
번호와 아이디 기반으로 variable 재조합 (결국 원본으로 돌아감)
cast(m_data, no + id ~ variable)
💻 출력결과
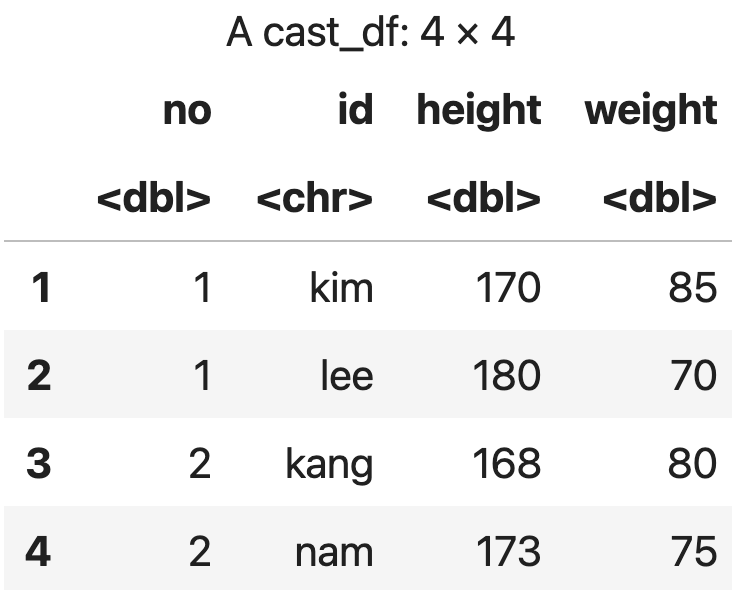
번호와 variable, 아이디 기준으로 조합
cast(m_data, no + variable ~ id)
💻 출력결과
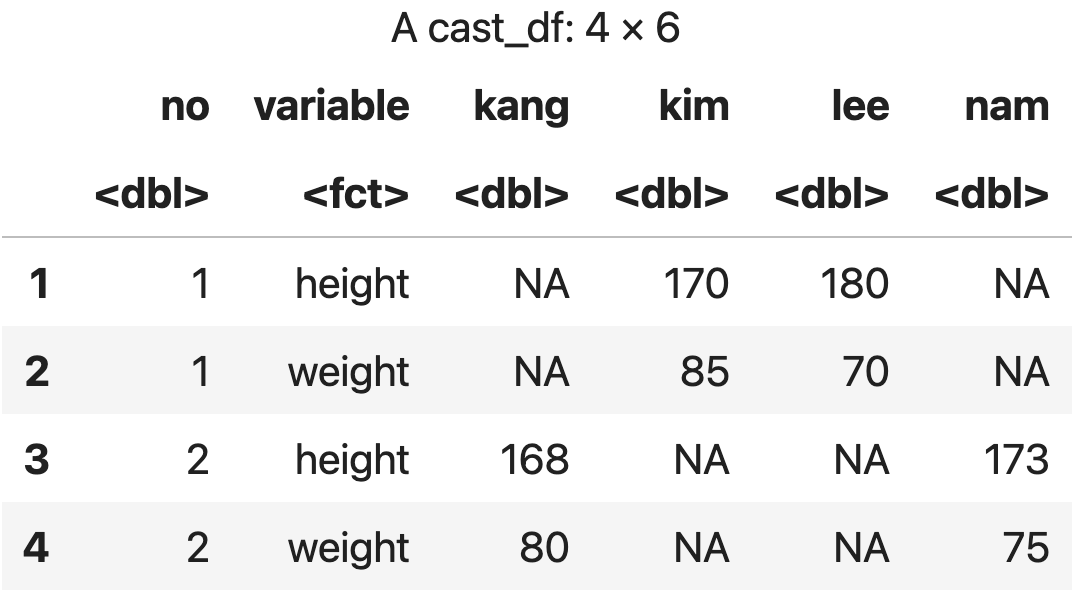
아이디와 variable에 따른 평균
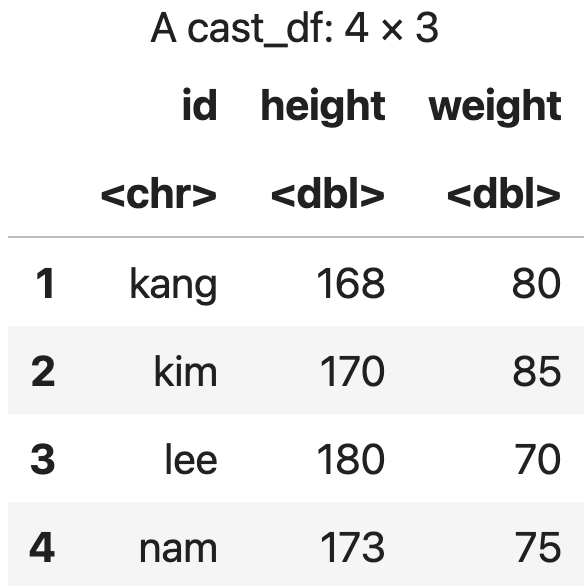
cast(m_data, id~variable, mean)
💻 출력결과
#03. respahe2 활용
피벗 테이블 구성 기능을 제공하는 패키지.
피벗 테이블 : 데이터 열 중 두 개의 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 재배치 한 것.
1) 필요한 기본 패키지와 샘플 데이터 준비
패키지 가져오기
REPO_URL <- "https://cran.seoul.go.kr/"
if (!require("reshape2")) install.packages("reshape2", repos=REPO_URL)
library(reshape2)
샘플 데이터 구성
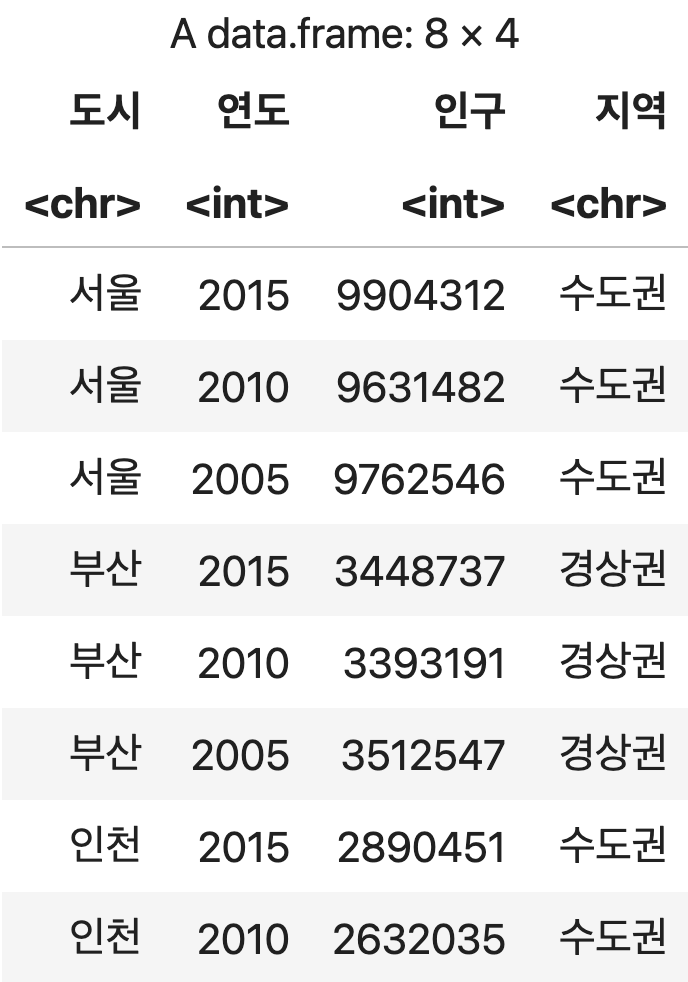
인구조사 <- read.csv("https://data.hossam.kr/r/city_people.csv", stringsAsFactors=F, fileEncoding="euc-kr")
인구조사
💻 출력결과
2) dcast() 함수를 사용한 피벗테이블 만들기
구문 형식
도시와 년도에 따른 인구수 피벗 테이블 만들기
dcast(인구조사, 도시~연도, value.var="인구")
💻 출력결과
3) 피벗 테이블 생성 제약
중복되는 경우에 대한 경고
컬럼과 인덱스이름으로 사용되는 데이터의 쌍이 중복되는 경우가 있다면 처리할 수 없다. (중복되는 데이터의 수량을 카운트 함)
아래의 코드는 “수도권-2010”, “수도권-2015”의 경우가 각각 두 쌍씩 존재하므로 경고가 표시된다.
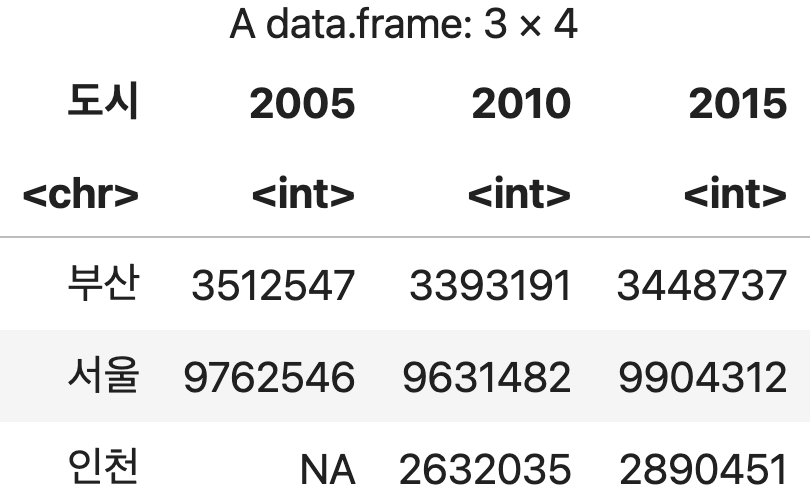
지역과 연도에 따른 인구수 피벗 테이블 (생성 에러)
dcast(인구조사, 지역~연도, value.var="인구")
💻 출력결과

해결책
중복되는 항목에 대한 처리 규칙을 명시하지 않아서 발생한 경고이므로 fun.aggregate 파라미터를 사용해서 중복 항목에 대한 집계 함수를 정의해 준다.
지역과 연도에 따른 인구 피벗 테이블 (중복되는 조합에 대한 평균치 산출)
dcast(인구조사, 지역~연도, value.var="인구", fun.aggregate=mean)
💻 출력결과
4) 그룹분석 결과를 피벗테이블로 조합하기
그룹조회 결과로 생성된 데이터프레임을 다시 dcast() 함수를 사용해 가공한다.
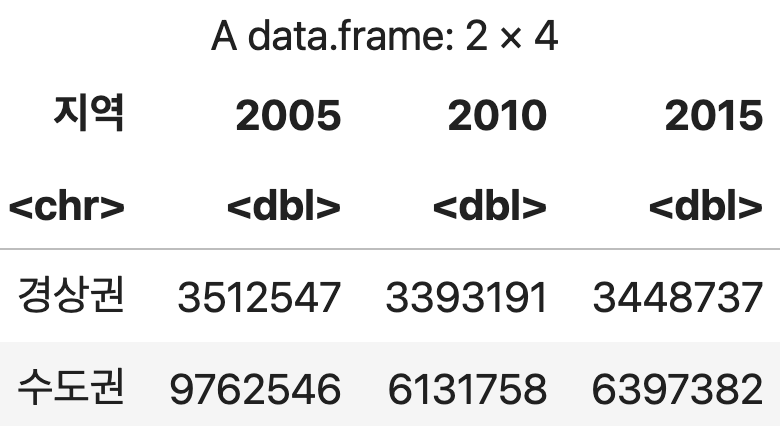
지역과 연도에 따른 평균 인구수
df <- 인구조사 %>%
group_by(지역, 연도) %>%
summarise(평균인구=mean(인구, na.rm=TRUE), .groups='keep')
pivot <- dcast(df, 지역~연도, value.var="평균인구")
pivot
💻 출력결과
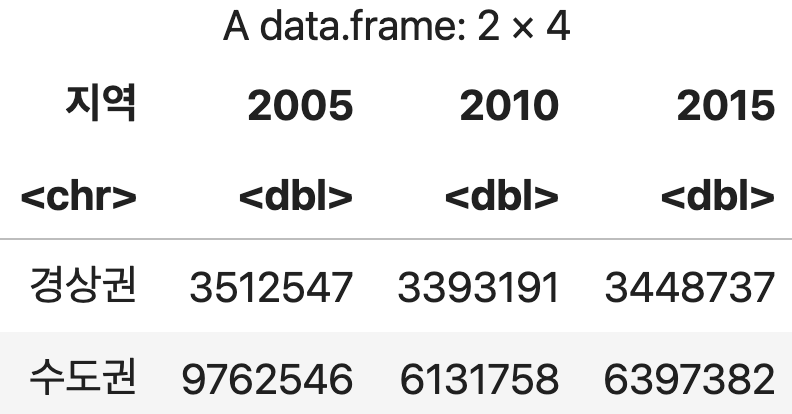
일반적으로 축약해서 사용하면 아래와 같다.
지역과 연도에 따른 평균 인구수 (요약코드)
dcast(인구조사 %>%
group_by(지역, 연도) %>%
summarise(평균인구=mean(인구, na.rm=TRUE), .groups='keep'),
지역~연도, value.var="평균인구")
💻 출력결과