![[R] 데이터프레임(DataFrame)](/images/posts/index-r.png)
[R] 데이터프레임(DataFrame)
데이터프레임(DataFrame)은 행과 열로 구성된 사각형의 표 형식의 자료구조로서 데이터 분석에서 가장 유용하며 필수불가결한 자료형입니다. 데이터프레임이라는 용어가 낯설다면 엑셀과 같은 분석 프로그램의 시트(sheet) 데이터를 구현하기 위한 자료형이라고 생각하면 이해하기 쉽습니다.
#01. 데이터 프레임의 이해
1) 데이터 프레임 기본 구조
엑셀의 표 형태로 구성된 데이터분석의 가장 기본적인 자료구조
열과 행으로 구성되며 열 > 행 순으로 값에 접근한다.
- 열: column이나 변수라고도 부름
- 행: row나 index라고도 부름
2) 데이터프레임과 행렬
공통점
- 데이터프레임과 행렬은 모두 2차원 데이터이다.
차이점
- 데이터프레임의 각 열은 서로 다른 자료형이 될 수 있다.
- 데이터프레임은 열 이름, 행 이름을 가질 수 있다.
#02. 데이터프레임 생성하기
- 벡터를 통한 생성
- 텍스트 파일을 통한 생성
- csv파일 로드하기
- 엑셀파일 로드하기
1) 벡터를 활용한 생성
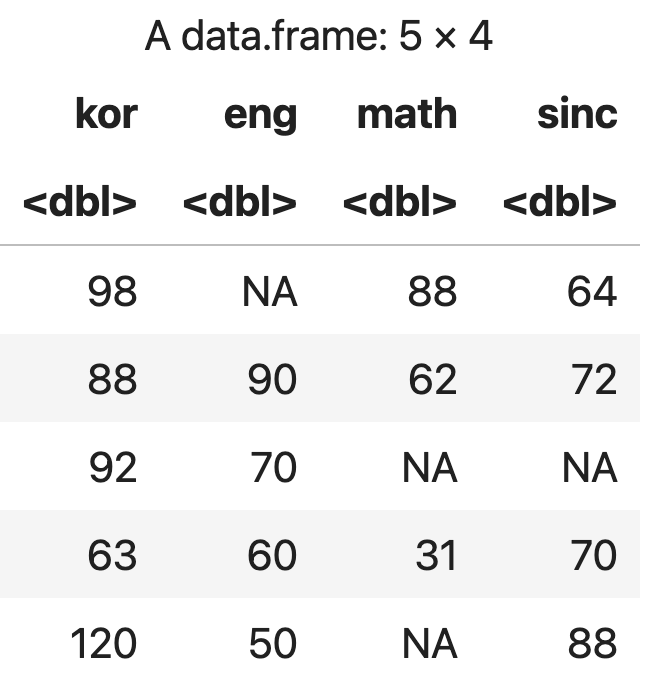
열로만 구성되는 데이터 프레임 생성
data.frame()함수에 여러 개의 벡터를 설정한 결과를 반환받는다.
kor <- c(98, 88, 92, 63, 120)
eng <- c(NA, 90, 70, 60, 50)
math <- c(88, 62, NA, 31, NA)
sinc <- c(64, 72, NA, 70, 88)
성적표 <- data.frame(kor, eng, math, sinc)
성적표
💻 출력결과
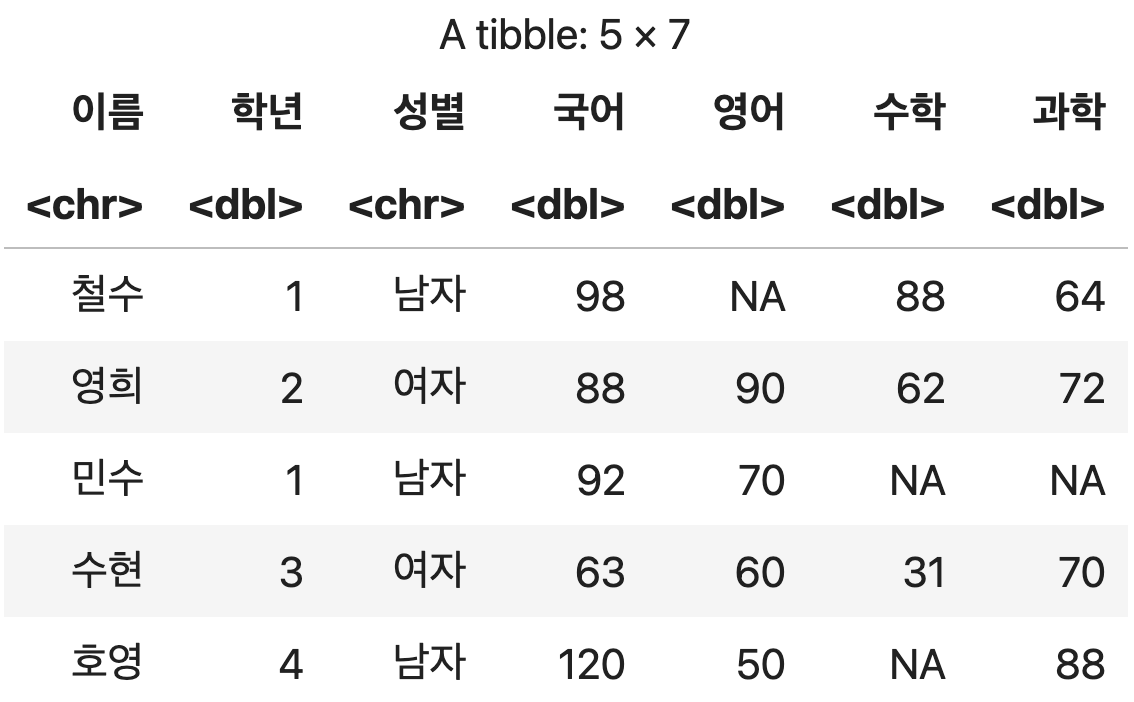
행, 열의 이름을 갖는 데이터 프레임 생성하기
행 이름 지정하기
data.frame()함수에row.names파라미터를 지정하고, 각 행의 이름을 벡터로 설정한다.- 데이터 분석에서 행을 의미하는 용어들: 인덱스(index), 로우(row)
- Python에서는 데이터프레임에 대한 인덱스가 정해져 있는 것이 분석에 유리하지만 R에서는 인덱스를 사용하지 않는 것이 더 유리하다.
열 이름 지정하기
data.frame()함수에 설정되는 각각의 벡터를이름=벡터형식으로 명시한다.- 데이터 분석에서 열을 의미하는 용어들: 컬럼(column), 변수(value)
kor <- c(98, 88, 92, 63, 120)
eng <- c(NA, 90, 70, 60, 50)
math <- c(88, 62, NA, 31, NA)
sinc <- c(64, 72, NA, 70, 88)
성적표 <- data.frame(국어=kor, 영어=eng, 수학=math, 과학=sinc,
row.names=c("철수", "영희", "민수", "수현", "호영"))
성적표
💻 출력결과
2) 텍스트 파일 가져오기
- 각 컬럼이 탭키로 구분되는 형식의 텍스트 파일을 데이터 프레임으로 변환한다.
구문형식
read.table(file, # 가져올 파일의 경로 혹은 URL (필수)
header = TRUE|FALSE, # 첫 번째 행을 헤더로 사용할 것인지 여부 (기본값=FALSE)
sep = "" # 각 열을 구분하는 글자 (필수)
row.names = c(...), # 행 이름 설정.
col.names = c(...), # 열 이름 설정.
na.strings = "NA", # NA 처리를 하고자 하는 문자열 지정
stringsAsFactors = default.stringsAsFactors(), # 문자열 컬럼의 팩터화 여부
fileEncoding = "utf-8|euc-kr") # 파일 인코딩 (Mac을 사용할 경우 필수)
가져오고자 하는 텍스트 파일 확인
https://blog.hossam.kr/data/grade.txt
이름 학년 성별 국어 영어 수학 과학
철수 1 남자 98 88 64
영희 2 여자 88 90 62 72
민수 1 남자 92 70
수현 3 여자 63 60 31 70
호영 4 남자 120 50 88
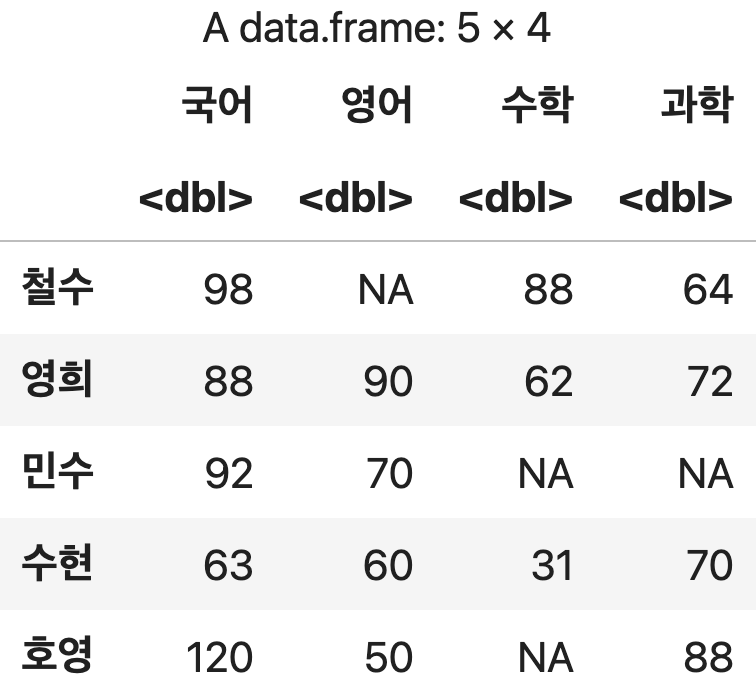
기본값들로만 처리하는 경우
성적표txt <- read.table("https://blog.hossam.kr/data/grade.txt",
sep='\t', fileEncoding="euc-kr")
성적표txt
- 텍스트 파일의 첫 행부터 데이터로 인식되고 각 컬럼의 이름은 임의로 지정된다.
- 빈 값도 하나의 데이터로 인식된다.
💻 출력결과
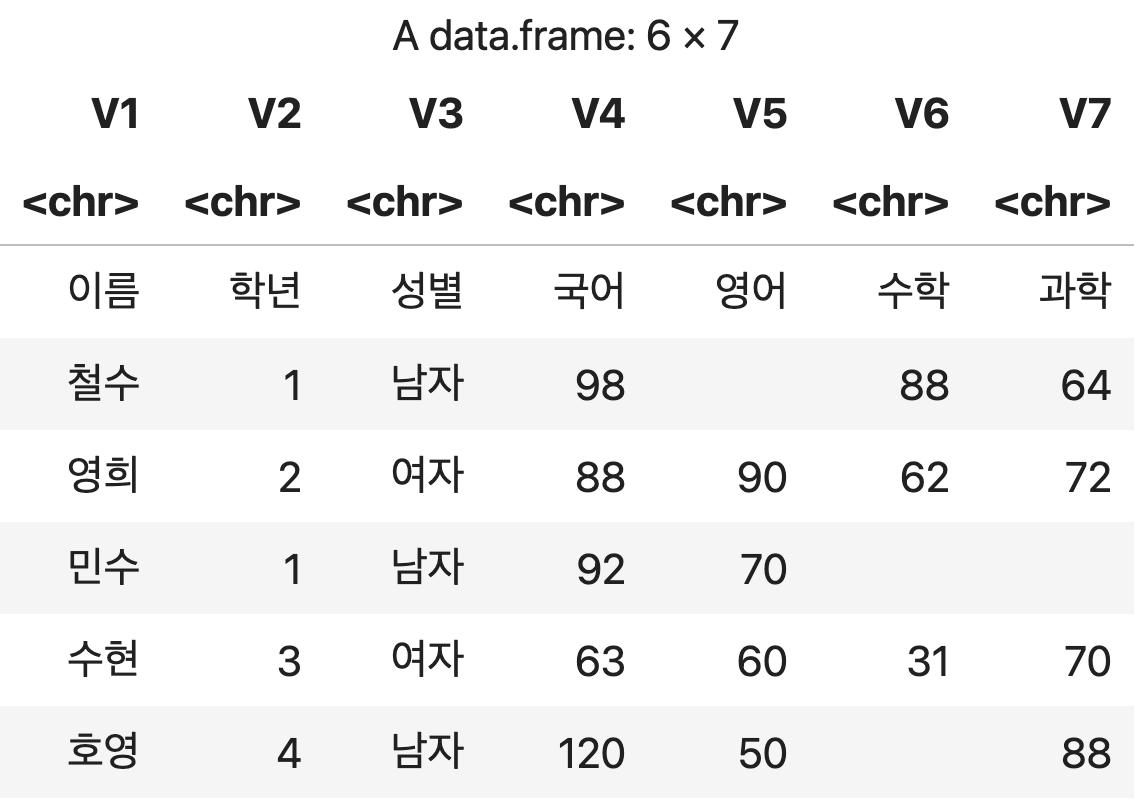
옵션을 적용하여 텍스트 파일로부터 데이터프레임 생성하기
성적표txt <- read.table("https://blog.hossam.kr/data/grade.txt",
sep='\t', header=TRUE, na.strings="", fileEncoding="euc-kr")
성적표txt
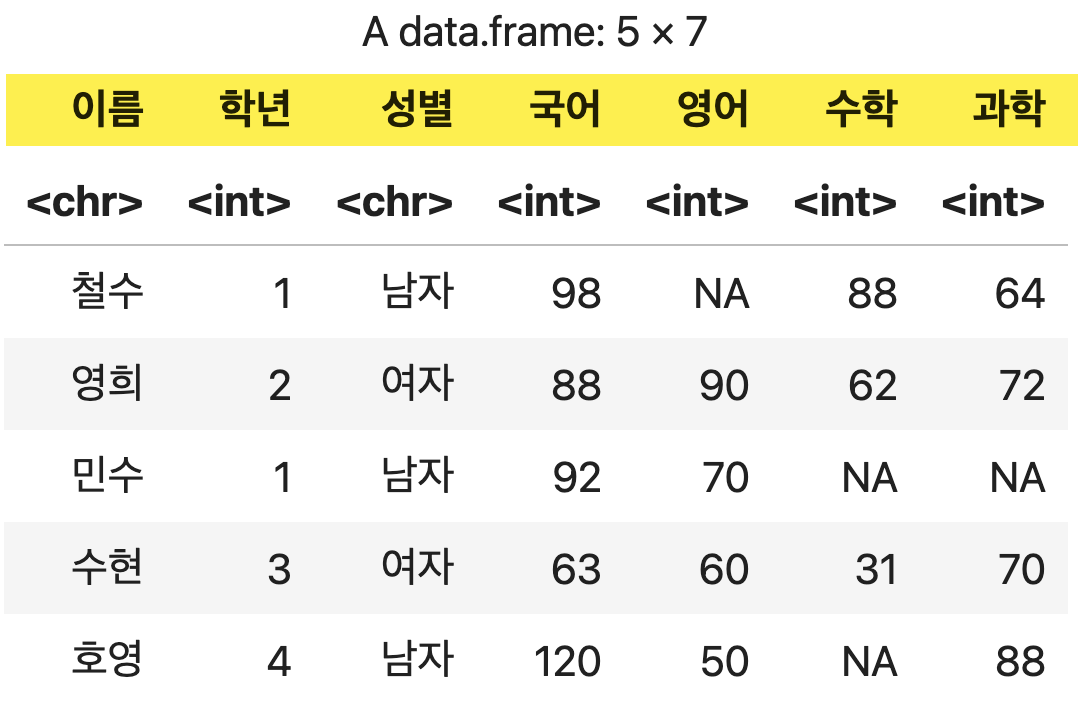
- header=TRUE : 텍스트 파일의 첫 번째 라인을 컬럼 이름으로 사용할지 여부
- na.strings=”“ : 빈 칸을 결측값(NA)으로 인식
- 대부분의 경우 권장하는 방식
💻 출력결과
💡 텍스트 파일의 첫 행이 컬럼 이름으로 사용되었음을 알 수 있다.
3) csv 파일 읽기
구문형식
read.csv(file, # 가져올 파일의 경로 혹은 URL (필수)
header = TRUE|FALSE, # 첫 번째 행을 헤더로 사용할 것인지 여부 (기본값=TRUE)
sep = "," # 각 열을 구분하는 글자 (기본값=콤마',')
row.names = c(...), # 행 이름 설정.
col.names = c(...), # 열 이름 설정.
na.strings = "NA", # NA 처리를 하고자 하는 문자열 지정
stringsAsFactors = default.stringsAsFactors(), # 문자열 컬럼의 팩터화 여부
fileEncoding="utf-8|euc-kr") # 파일 인코딩 (Mac을 사용할 경우 필수)
기본적으로 read.table() 함수와 동일하지만 sep 옵션이 콤마(,)로 기본 지정되어 있으며 header 옵션의 기본값이 TRUE로 지정되어 있다.
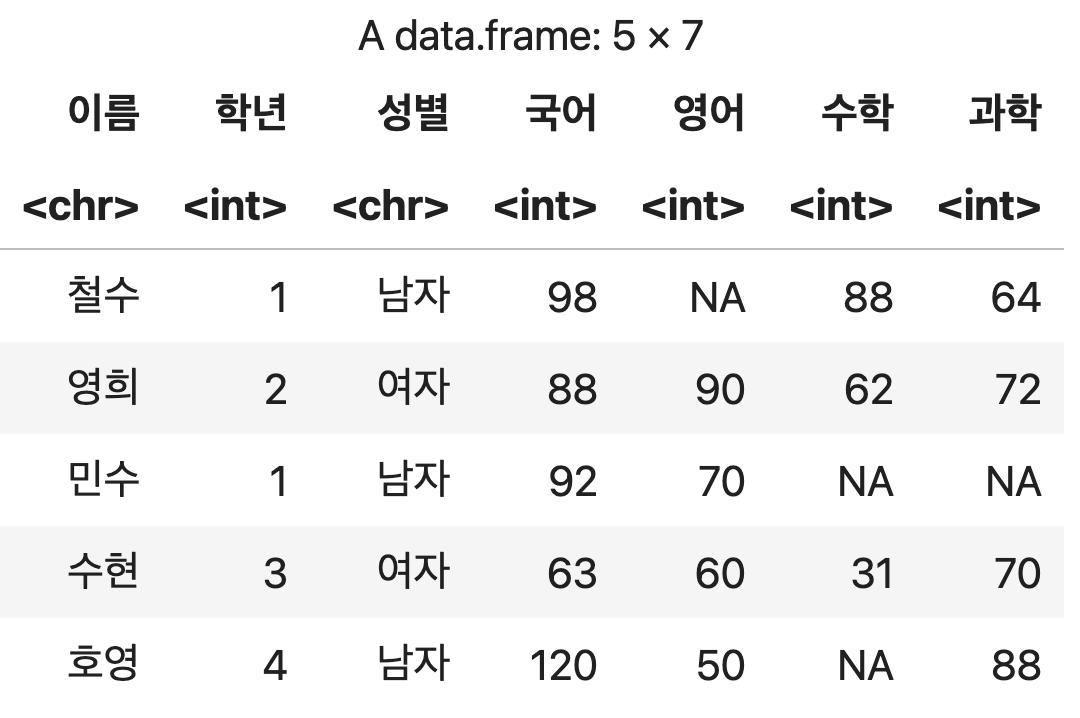
CSV 파일을 기반으로 한 데이터프레임 생성
# -> header=FALSE 옵션을 추가하면 첫 줄이 컬럼이름으로 인식되지 않고 일반 데이터로 인식된다.
성적표csv <- read.csv("https://blog.hossam.kr/data/grade.csv",
stringsAsFactors=FALSE, fileEncoding="euc-kr")
성적표csv
💻 출력결과
4) 엑셀파일 가져오기
엑셀파일을 처리하기 위한 패키지 설치 및 로드
💡 패키지는 일종의 확장팩이라고 이해하면 쉽습니다. 패키지에 대한 내용은 뒤에서 별도로 정리할 것이므로 여기서는 일단 아래 구문을 그대로 입력하고 넘어가겠습니다.
REPO_URL <- "https://cran.seoul.go.kr/"
if (!require(readxl)) install.packages("readxl", repos=REPO_URL)
library(readxl)
💻 출력결과
패키지 다운로드 과정이 최초 1회만 표시되며 그 후부터는 아무런 결과도 표시되지 않는다.
엑셀파일을 가져오기 위한 구문 형식
# 원격지의 파일을 내려받기
download.file(파일URL, **저장할파일경로**, mode='wb')
# 내려 받은 파일을 데이터 프레임으로 변환하기
read_excel(**저장된파일경로**, # 엑셀파일의 경로 (필수)
sheet="...", # 읽어올 시트의 이름 (필수)
range = "...", # 읽어들일 범위 (ex: A1:D19)
col_names = TRUE) # 엑셀의 첫 행을 컬럼이름으로 사용할지 여부(기본값=True)
- 원격지의 엑셀 파일을 가져와야 하는 경우
download.file(URL, 저장할파일이름, mode='wb')함수를 사용하여 파일을 내려받은 후 읽어들일 수 있다. mode='wb'가 지정되지 않을 경우 다운받은 파일을 압축 파일로 인식한다.- 다운로드 처리를 하지 않는 경우 텍스트나 csv와 달리 현재 컴퓨터에 저장되어 있는 파일만 가져올 수 있다.
온라인 상의 엑셀파일을 기반으로 한 데이터 프레임 생성
# 저장할 파일 이름
filename <- 'helloworld.xlsx'
# 엑셀 파일 다운로드 받기
download.file("https://blog.hossam.kr/data/grade.xlsx", filename, mode='wb')
# 다운로드 받은 파일을 데이터 프레임으로 변환
성적표xlsx <- read_excel(filename, sheet="grade")
# 결과 출력
성적표xlsx
💻 출력결과