![[R] 변수와 데이터 타입](/images/posts/index-r.png)
[R] 변수와 데이터 타입
변수란 R에서 취급하는 데이터를 표현하는 단위 입니다. 이 데이터를 활용하여 각종 연산을 수행할 수 있는데 이 때 사용되는 특수기호들을 연산자라고 합니다.
#01. R에서 사용되는 데이터의 종류
- 변수: 변할 수 있는 수 (일반적인 프로그래밍에서 사용되는 개념)
- 스칼라: R에서 프로그래밍의 변수를 부르는 용어
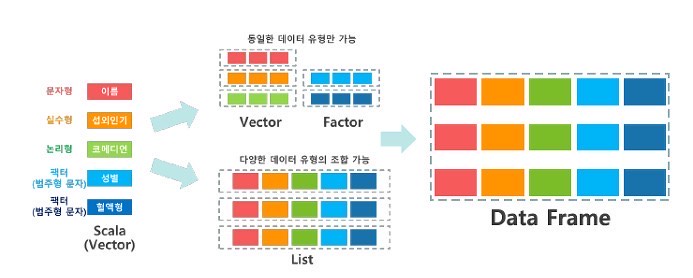
1) 스칼라
| 이름 | 설명 |
|---|---|
| 숫자형 | 기본적으로 실수 형식. 정수로 표현하기 위해서는 숫자값 뒤에 L을 표시해야 함. |
| 논리형 | 참(TRUE), 거짓(FALSE) 중 하나를 갖는 값. |
| 문자열 | 쌍따옴표나 홑따옴표로 감싼 문장 |
2) 같은 종류의 값들로 구성되는 그룹 형태의 데이터
| 이름 | 설명 |
|---|---|
| 백터 | 같은 종류의 값들을 c 라는 명령어로 묶어서 나열. → 벡터들은 동질적이다. |
| 행렬 | 백터를 나열한 형태 |
| 요인 (factor) | 범주를 갖는 값. ex) 성별, 도시이름 등 |
3) 서로 다른 종류의 값들로 구성
| 이름 | 설명 |
|---|---|
| 리스트 | 서로 다른 종류의 값들을 그룹으로 묶어 놓은 형식으로 일반적인 프로그래밍 언어에서 말하는 배열의 개념이다. |
4) 최종 형태
| 이름 | 설명 |
|---|---|
| DataFrame | 데이터 분석을 위한 종합적인 자료형. 엑셀 시트를 생각하면 좋다. |
#02. 함수
프로그램 코드를 하나의 명령으로 그룹화 한 재사용 가능한 단위
$f(x) = x + 1$
| 이름 | 명칭 | 수학에서의 의미 | R에서의 의미 |
|---|---|---|---|
| $x$ | 변수 | 변할 수 있는 수 | 분석가가 정의한 데이터 |
| $f$ | 함수 | 정의된 조건값($x$)이 활용되는 수식을 재사용하기 위한 단위. | R에서 제공하는 기본 기능 |
#03. 스칼라 값의 기본 자료형
- 아래의 형식으로 변수를 정의할 수 있다.
- 이름은 각자 편의에 따라 정의하면 된다.
이름 <- 값형식으로 임의의 데이터를 저장할 수 있다.
1) 문자형(character)
- 쌍따옴표나 홑따옴표로 감싸진 문장 형태의 데이터
- 주어진 내용을 출력하는
print()함수를 사용하여 내용을 출력할 수 있다.
변수 만들고 출력하기
char <- "Hello World"
print(char)
💻 출력결과
[1] "Hello World"
2) 스칼라 값의 종류 확인하기
typeof()함수는 주어진 값의 종류를 반환한다.
typeof() 함수를 활용한 스칼라 값의 종류 확인
char <- "Hello World"
type <- typeof(char)
print(type)
💻 출력결과
[1] "character"
3) 숫자형
숫자형에는 실수(double)형태와 정수(integer) 형태가 있다.
실수 형태의 값 사용하기
R에서는 기본적으로 모든 숫자 형태의 값을 실수로 인지한다. 정수를 대입하더라도 실수로 식별한다.
number1 <- 123
print(number1)
# 함수가 중첩 사용되는 경우 안쪽의 함수부터 실행된다.
print(typeof(number1))
💻 출력결과
[1] 123
[1] "double"
소수점을 갖는 실수형 스칼라 값
number2 <- 3.14
print(number2)
print(typeof(number2))
💻 출력결과
[1] 3.14
[1] "double"
정수(integer)형 스칼라 값
정수형을 사용하기 위해서는 숫자 뒤에 알파벳 대문자 L을 명시적으로 적용해야 한다.
number3 <- 123L
print(number3)
print(typeof(number3))
💻 출력결과
[1] 123
[1] "integer"
3) 논리형 (logical 혹은 boolean)
- 참(TRUE), 거짓(FALSE). 영어 대문자만 사용해야 함.
논리값 확인하기
is <- TRUE
print(is)
print(typeof(is))
💻 출력결과
[1] TRUE
[1] "logical"
3) 특수한 형태의 값
NULL 값 확인하기
- NULL이란 결정되지 않은 값을 의미한다.
- 데이터의 값이 아직 존재하지 않는다 뜻이다.
sp1 <- NULL
print(sp1)
print(typeof(sp1))
💻 출력결과
[1] NULL
[1] "NULL"
NA(손실값,결측값)
- Missing value. 결측값, 손실된 값.
sp2 <- NA
print(sp2)
print(typeof(sp2))
💻 출력결과
[1] NA
[1] "logical"
NaN(숫자가 아닌 값)
Not a Number - 수학적으로 정의되지 않은 값
sp3 <- NaN
print(sp3)
print(typeof(sp3))
💻 출력결과
[1] NaN
[1] "double"
Inf(무한대)
잘 사용되지 않는 값이다.
sp4 <- Inf
print(sp4)
print(typeof(sp4))
💻 출력결과
[1] Inf
[1] "double"
#04. 스칼라 값에 대한 연산자
1) 산술연산자(사칙연산자)
더하기
# 연산을 위해 사용될 스칼라 값 정의
x <- 5L
y <- 3L
print(x + y)
💻 출력결과
[1] 8
빼기
x <- 5L
y <- 3L
print(x - y)
💻 출력결과
[1] 2
곱하기
x <- 5L
y <- 3L
print(x * y)
- 💻 출력결과
[1] 15
제곱근
- 제곱근은
**연산자와^연산자 두 개가 존재한다. (차이 없음)
x <- 5L
y <- 3L
print(x ** y)
print(x ^ y)
💻 출력결과
[1] 125
[1] 125
나누기
/실수 부분까지 계산한다.%/%정수 부분의 몫만 취한다.%%나눗셈의 나머지만 취한다.
x <- 5L
y <- 3L
print(x / y)
print(x %/% y)
print(x %% y)
💻 출력결과
[1] 1.666667
[1] 1
[1] 2
2) 비교연산자
- 연산 결과가 참(TRUE) 혹은 거짓(FALSE) 형태로 나타남
같다(==), 다르다(!=)
# 연산을 위해 사용될 스칼라 값 정의
x <- 5L
y <- 3L
print(x == y) # 같은지 여부를 비교
print(x != y) # 다름을 비교
💻 출력결과
[1] FALSE
[1] TRUE
크기 비교
x <- 5L
y <- 3L
print(x < y) # 미만
print(x <= y) # 이하
print(x > y) # 초과
print(x >= y) # 이상
💻 출력결과
[1] FALSE
[1] FALSE
[1] TRUE
[1] TRUE
3) 논리연산자
AND (&)
- 모든 명제가 참인 경우만 결과가 참
print(TRUE & TRUE)
print(TRUE & FALSE)
print(FALSE & TRUE)
print(FALSE & FALSE)
💻 출력결과
[1] TRUE
[1] FALSE
[1] FALSE
[1] FALSE
OR (|)
- 하나라도 참인 명제가 있다면 결과가 참
print(TRUE | TRUE)
print(TRUE | FALSE)
print(FALSE | TRUE)
print(FALSE | FALSE)
💻 출력결과
[1] TRUE
[1] TRUE
[1] TRUE
[1] FALSE
비교식과 함께 AND (&) 연산자 사용하기
비교식의 결과는 그 자체가 참, 거짓을 의미하므로 비교식끼리 논리연산을 수행할 수 있다.
print(5 > 3 & 10 > 7) # TRUE & TRUE
print(5 < 3 & 10 > 7) # FALSE & TRUE
print(5 > 3 & 10 < 7) # TRUE & FALSE
print(5 < 3 & 10 < 7) # FALSE & FALSE
💻 출력결과
[1] TRUE
[1] FALSE
[1] FALSE
[1] FALSE
비교식과 함께 OR(|) 연산자 사용하기
print(5 > 3 | 10 > 7) # TRUE | TRUE
print(5 < 3 | 10 > 7) # FALSE | TRUE
print(5 > 3 | 10 < 7) # TRUE | FALSE
print(5 < 3 | 10 < 7) # FALSE | FALSE
💻 출력결과
[1] TRUE
[1] TRUE
[1] TRUE
[1] FALSE
논리값 부정 (!) –> NOT
- TRUE와 FALSE의 결과를 뒤집는다.
foo <- TRUE
bar <- !foo
print(bar)
💻 출력결과
[1] FALSE